Building a global deployment platform is hard, here is why
If you ever tried to go global, you have probably faced a reality check. A whole new set of issues starts to appear when you start to operate a workload over multiple locations across the globe:
- Orchestrating deployments across regions is difficult: what happens if you want to deploy a new version of your app and it is deployed correctly in some locations but not on other ones?
- You need to secure traffic between your components, distributed over the world: what technology do you choose? You need to maintain that now, too!
- Your distributed systems may stop working: when agents need to coordinate over a network, they often necessitate low latency. Hashicorp's Consul requires the average RTT for all traffic between its agents to never exceed 50ms.
- It requires expertise to manage the networking layer. How can you make sure that your components can correctly communicate with each other, especially if there are thousands of kilometers in between them or if some of them become irresponsive?
- And there are even more challenges!
So it looks like a great idea in theory, but in practice, all of this complexity multiplies the number of failure scenarios to consider!
Building a multi-region engine, so you don't have to
We previously explored how we built our own Serverless Engine and a multi-region networking layer based on Nomad, Firecracker, and Kuma. Put on your scuba equipment, this is now a deep dive into our architecture and the story of how we built our own global deployment engine!
Step 0: Our original engine supported deployments in only one region
Multi-region or not, whenever you want to deploy an application on our platform, it all begins with a POST API call against our API with the desired deployment definition. A deployment definition describes how your app should be deployed and roughly looks like this:
{
"name": "my-cool-website", // Name of your Koyeb Service
"type": "WEB",
"routes": [
{
"port": 3000, // Your code should listen on port 3000
"path": "/" // All requests made to the URL of your site will be routed by Koyeb to port 3000 of your application
}
],
"ports": [
{
"port": 3000,
"protocol": "http"
}
],
"docker": {
"image": "docker.io/koyeb/demo", // The container image to use
"command": "",
"args": []
}
// And more stuff...
}
Our API server stores this in a database and a Golang worker starts an elaborate boot process. The schema belows describes the components at play.
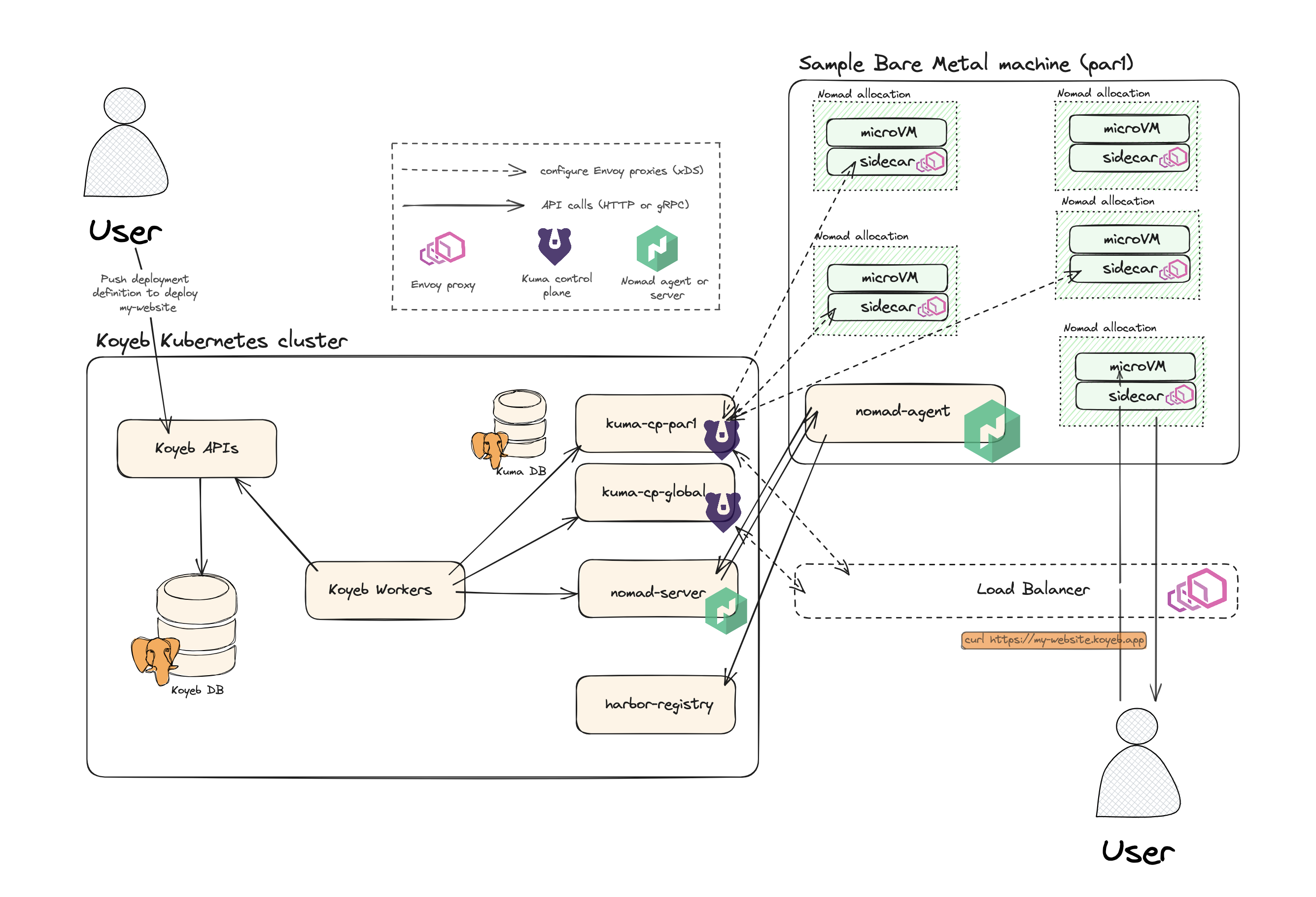 |
|---|
| Original architecture we ran to manage apps |
Our tech stack is centered around Nomad, Kuma and good ol' Golang
That is a lot of components, isn't it? If you're curious about our core engine, we previously wrote about why and how we built it on top of bare metal servers with Nomad, Firecracker, and Kuma. In the meantime, let's quickly go over what each of those do:
-
Workers: a set of long-running Golang programs. They orchestrate the boot process by talking to a bunch of services to bring an Instance to life
-
APIs: gRPC webservers, written in Golang. They are the layer around the database to manipulate our resources
-
A database: your typical PostgreSQL database
-
Harbor: a container image registry. It holds the container images that we build out of GitHub repositories
-
Nomad: a flexible scheduler and orchestrator. It can deploy and manage jobs on servers. We use a custom driver to make it deploy Firecracker microVMs, where each microVM is an Instance. It is split into two parts:
- Nomad Servers: a set of Golang programs. Nomad Servers expose an API to deploy, upscale, edit and delete jobs
- Nomad Agent: a lightweight Golang program that runs on a machine. It is the one that actually spawns the needed microVM(s). It constantly chit-chats with a Nomad server: it takes orders and reports the current state of the Jobs on its machine
Both Nomad Agent and Nomad Server work hand in hand to ensure that, at all times, the required applications are running across the fleet of servers. If a machine fails, Nomad Server will ask other Agents on other machines to take over the work
-
Kuma: a service mesh. It powers the network layer of Instances: a mesh in which all Instances of a user can communicate with every other Instance through robust, secure, private networking.
- For each Instance, Kuma provisions a sidecar. It intercepts inbound traffic and treats it as ordered by the mesh configuration. For example, if the MicroVM were to receive a request from an unauthorized peer, the sidecar would deny it
- Each sidecar must be connected to a zonal control plane to retrieve its mesh's configuration. In turn, all zonal control plane communicate with a global control plane to synchronize its view of the world
Both Nomad Agents / Nomad Servers and Kuma Sidecars / Kuma Regional CPs are constantly talking to each other. They are the core part needed to boot and manage the daily life of Instances.
We wanted to deploy a region in North America and had future plans to expand all over the world. We could not let those core components and our machines communicate over the Atlantic or other long distances 🙂. In fact, the network bandwidth would have been costly and the Nomad and Kuma streams latency would have gotten too high. We also had plans to build regions all around the world, so this problem was bound to happen again.
So, we had to build a multi-region system!
Step 1: Agreeing on a target vision for a multi-region engine
** Major architectural changes like this have a long-lasting impact: these decisions can be carried over during 10 years. We needed a future-proof architecture that would hold its ground for at least two or three years to come and support at least 25 locations, actually up to 100 locations.**
Our goals: efficiency, agility, resiliency (aka better, faster, stronger)
We first laid down our requirements and wishes. Our three main wishes were to:
- Provision new regions fast: our goal is to have dozens of locations available for our users, so it should be business as usual to spawn new locations
- Sustain partial outages:
- A failing region should not bring down our infrastructure as a whole
- A failure in Koyeb components should not affect the workloads of our users
- Reach our target architecture gradually: we wanted to start deploying new regions in the coming months, not years. Hence, we wanted to be able to ship a first version fast but that we could iterate on to improve over time
Given these requirements, we started exploring different ideas.
- Decentralized architecture: We have plans to deploy components all around the world. The physical distance between these components will lead to high latencies, which would make this architecture challenging to maintain.
- Dedicated virtual machines per region: We thought about having dedicated virtual machines which would host just some core services like Kuma, nearby the bare metal machines. It was tempting because of the low cost. However, we ruled it out too because we thought that we probably would need to enlarge those VMs to host more and more services over time and that this wouldn't be flexible with a non-negligeable cost of maintenance.
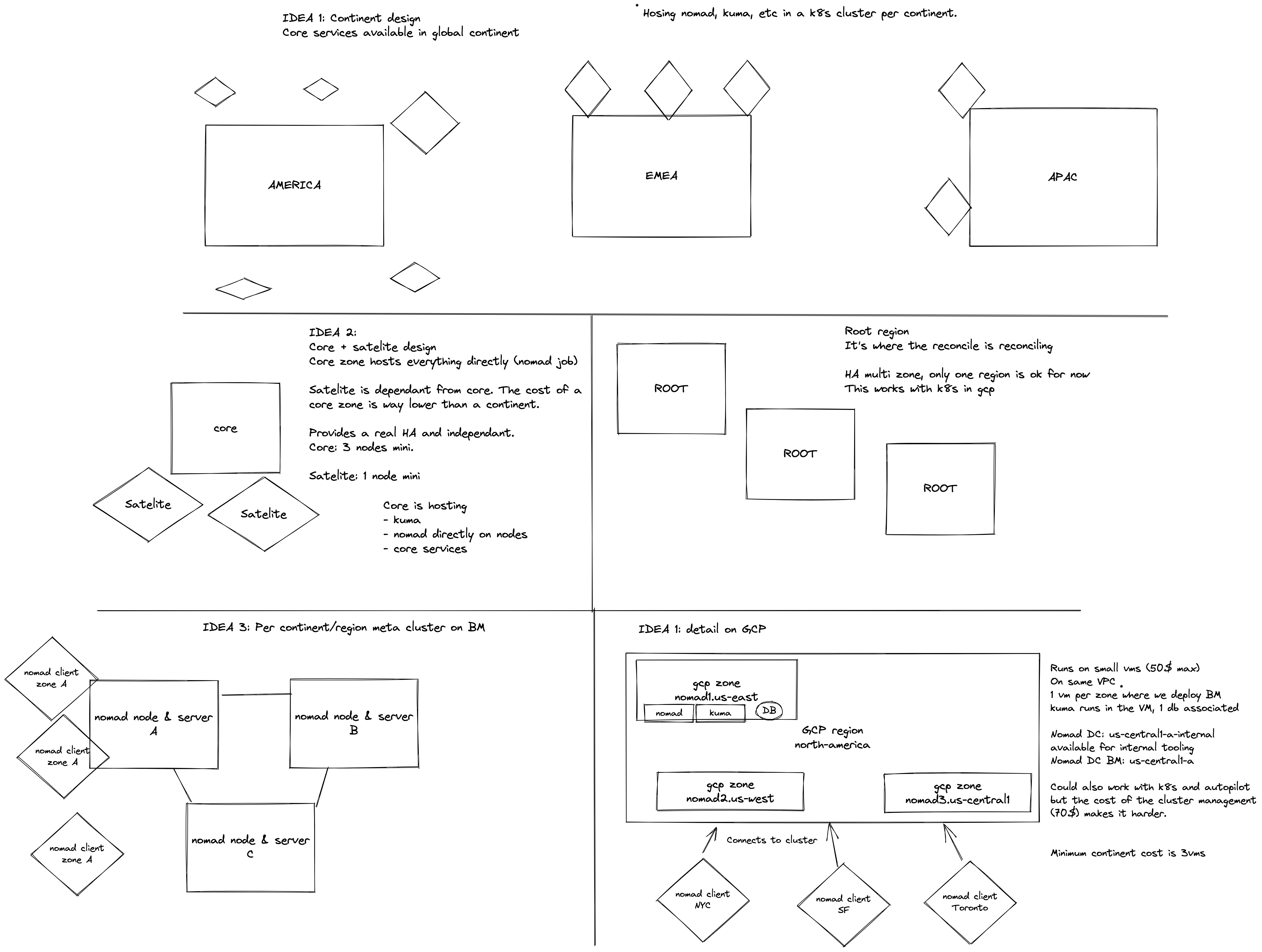 |
|---|
| Some early ideas that we had |
Topology: global, continental, regional and data center level components
In the end, we settled on a federated-like hierarchy to distribute our systems around the world: one global component, to which are attached a few smaller components, to each are attached a few smaller components, and so on.
The great thing about federation is that it is simple. The problem is that your global component does not scale well. We tried to shoot for something "in-between" that would allow us to move the stuff that does not scale well from the top-level components to the lower-level ones.
We defined 4 kinds of components scopes: global, continental, regional, data center-level and settled down on the following topology:
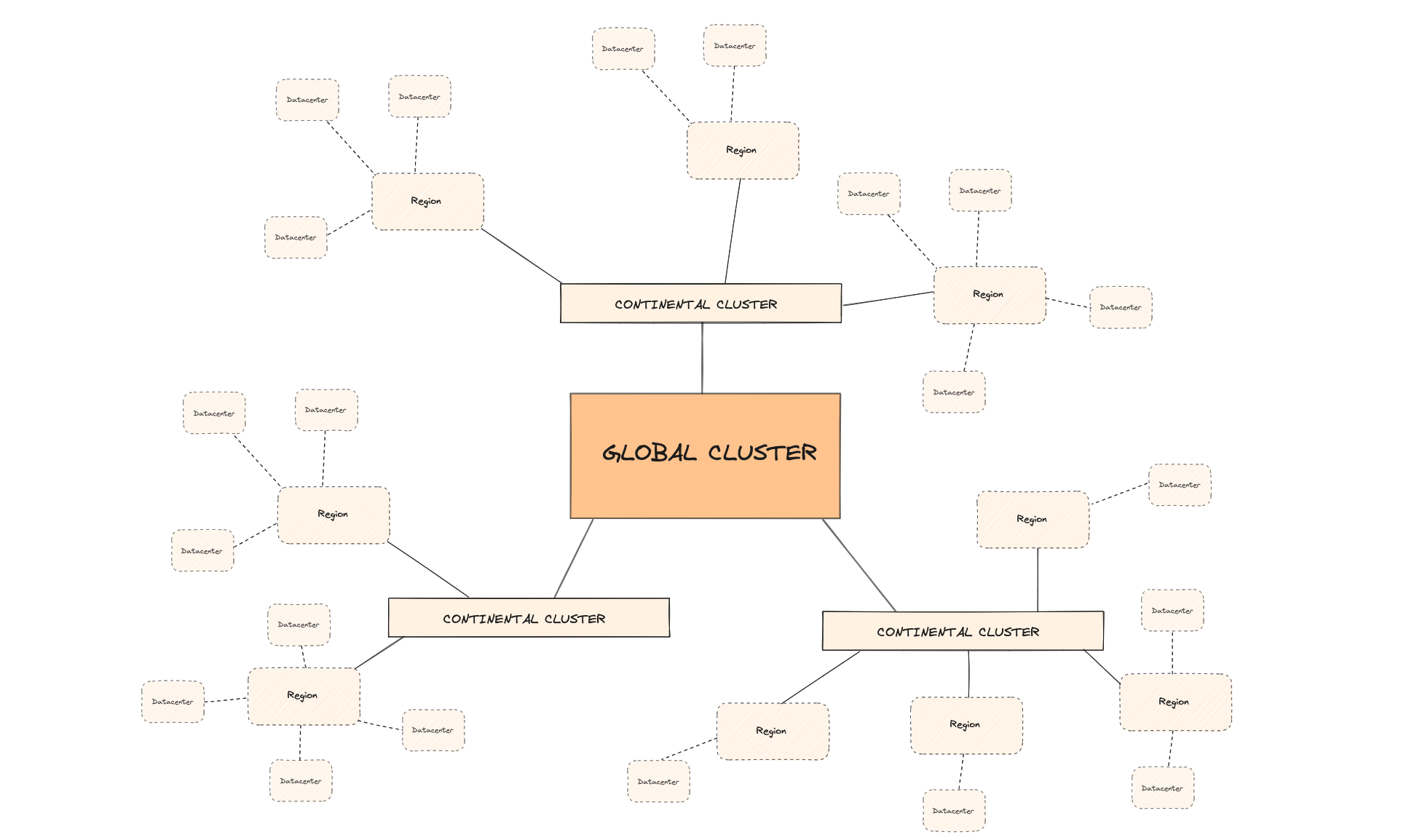 |
|---|
| Target topology |
- A data center (e.g.
was1) would be an aggregate of 1 to thousands of bare metal servers - A region (e.g.
wasfor Washington) would be:- a lightweight, control plane constituted of Nomad Servers and Kuma Zonal control planes...
- ...controlling a few data centers, all geographically close to each other
- A continent (e.g.
nafor North America) would be a deployment cluster. It would have no inherent value but be a platform where we could host the control planes of regions in such a way that those are geographically close to the data centers they manage - Finally, our global Kubernetes cluster would be the global control plane for the World™. It would host resources that are unique across the platform: an account on our platform, the definition of an App, our main database, the billing system…
Designed for low latency where it matters: for now, our most critical need is low latency between the data centers and Nomad/Kuma.
-
Continental clusters would host regional control planes, ensuring all data centers have a latency ≤ 40ms (maximum ≤ 60-70ms) to their respective control planes.
-
Our APIs and workers would live on the global cluster in 99% of the cases. This is fine because they would perform synchronous, but not latency-critical, calls to the regional control planes.
As a rule of thumb, bare metal machines would exclusively contact their regional control planes and users of the platform would exclusively interact with APIs on the global cluster.
Gradually reach target infrastructure: with this idea, we have low latency for our most critical components. Tomorrow, we can go further. The endgame over time is to move more and more stuff from the global cluster to lower-level components.
Failure scenarios of this architecture
The way we answered the reliability problem was to consider each region as an independent satellite.
If a machine fails, the reliability of applications can be ensured by rescheduling Instances in other machines in the same data center. This is handled natively by Nomad.
If a data center fails, the reliability of applications can be ensured by rescheduling Instances in other data centers of the same region. This is handled natively by Nomad too. Plus, we can define affinities in Nomad; they give us the flexibility to define in which data centers of a region an Instance can or cannot be rescheduled.
If a region suffers an outage, the reliability of applications can be ensured natively if they were deployed in other regions. The experience shall be a bit degraded but it would overall continue working.
If the global cluster suffers an outage, then, the deployment experience is affected: our public APIs would be unaccessible. However, the applications hosted on us would be unimpacted because they do not need to interact with the global cluster to operate. Increasing reliability of the global cluster is also easily doable to mitigate global deployment outages.
 |
|---|
| Actual depiction of what should happen during partial outages. Meme credit KC Green: https://gunshowcomic.com/648 |
Pick your poison: a tour of the trade-offs we took
Engineering is all about trade-offs and when we settled on this design, we had to make some:
-
There is a global cluster.
Our global cluster is there to host… global resources. Sounds like a weak link, right? It might be, but we believe that it is way easier to manage a global cluster and that we can greatly mitigate the impact of outages on this component.
First, the risks of an outage of that Kubernetes cluster are low because it can be distributed across multiple availability zones. Then, the target architecture just described allows regions (and continents) to run independently in case of a global cluster outage.
-
We decided to run one Nomad cluster per region.
Nomad allows us to natively reschedule Instances to some other servers if one of them crashes. Having one Nomad cluster per region effectively prevents us from leveraging its native failover policies to reschedule jobs across regions in case of regional outages. So, we have to handle that failure scenario by ourselves; that is more work.
On the other hand, we believe that it is key to achieving our vision of independent, satellite regions. Theoretically, a single Nomad cluster is supposed to be able to orchestrate thousands of tasks, all over the globe. However, by splitting the Koyeb World into multiple regions orchestrated by multiple Nomad clusters, we reduce the impact of a Nomad cluster failing.
A future-proof architecture designed around continuous improvement
This design allows us to iterate quickly and to progressively improve availability. Continental clusters have a privileged latency to bare metal machines (they are physically closer). We aim to move a lot of stuff there to improve performance and reduce costs.
For now, we settled on moving only the strictly necessary sotware on continental clusters (Kuma and Nomad). Over time, we will port more components there as we need it.
Step 2: Putting the “multi” in multi-region deployments
After all of this thinking, it was finally time to get our hands dirty! We laid down our specifications for the first version of our multi-regions deployment engine: keep it simple and migrate only the strictly necessary stuff over to continental clusters.
Before deploying a new region in the US, we decided to first make our European region comply with this new architecture.
At the time we had one single region. We decided to start from scratch with a new region, transparently migrate all of our users over there, and then bid farewell to the old setup. This was simpler than trying to build the target architecture while maintaining the original setup; a probably painful experience that we avoided.
We made very few changes to our original global cluster:
- We kept our current cluster in Europe and gave it the fancy title of global cluster
- We set up Istio with the Multiple Clusters deployment model to ease communication between global and continental clusters. With this, we let Istio secure those communications. Components could then address each other with just a domain name. With this, we can run HTTP requests to
http://nomad-api-access.fra:4646from the global cluster, for example
Frankfurt: the first region with the new architecture
We provisioned a new cluster, our European continental cluster. Then, we dedicated a Kubernetes namespace for the new Frankfurt region (fra).
In there, we put:
- A zonal kuma control plane, that we plugged to the global control plane
- A set of nomad servers for the region
We put a load balancer in front of nomad-server and kuma-cp because our bare metal machines would need to talk to them over the Internet. We protected those services with mutual TLS.
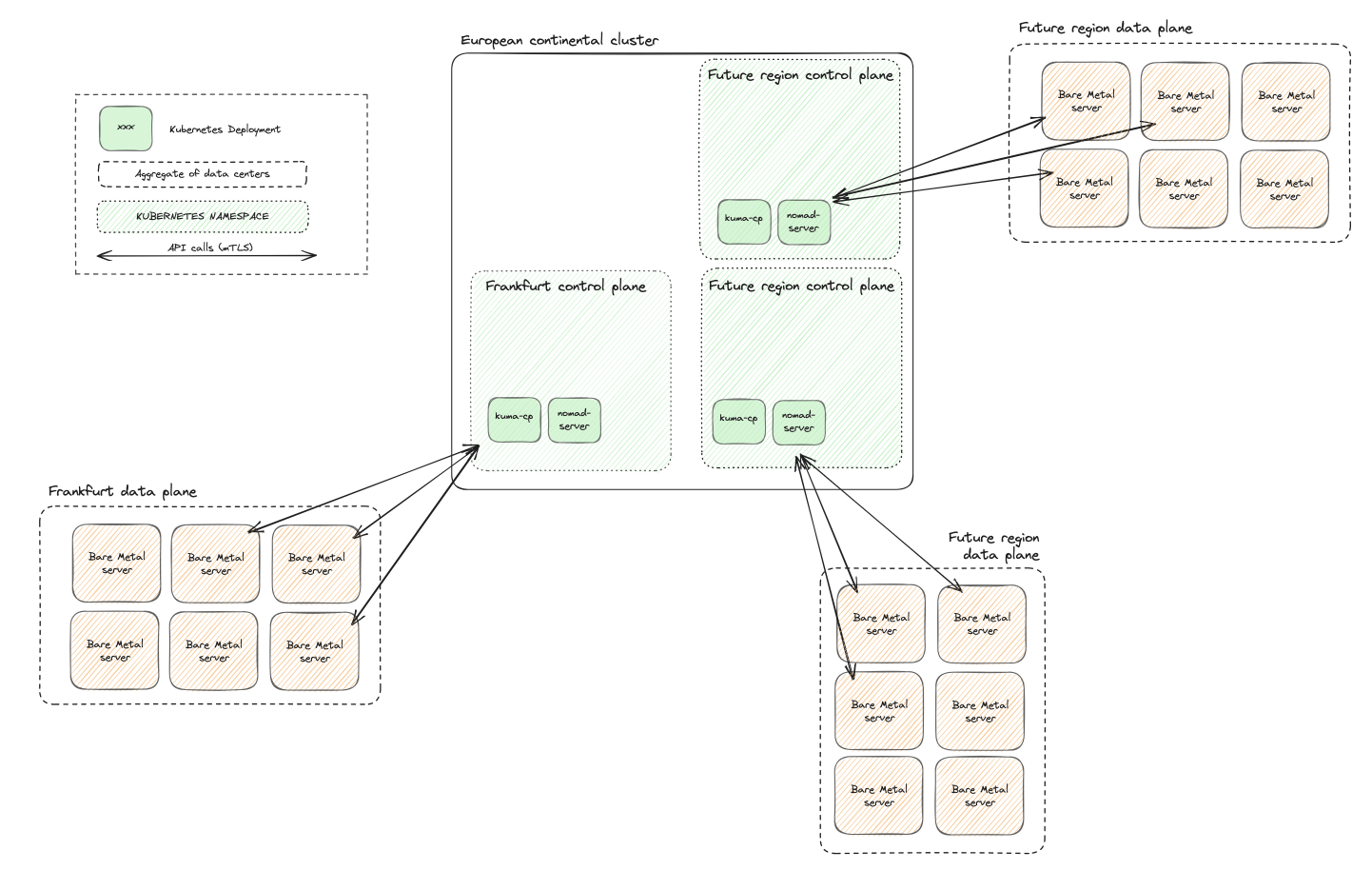 |
|---|
| Design of control planes |
This design makes it super easy to bootstrap a control plane. A control plane is simply a set of YAML manifests. We can then apply it to an existing continental Kubernetes cluster. It can be packaged in a Helm chart or a Kustomize configuration tree, for simplicity.
Finally, we deployed our data plane: a handful of bare metal machines located in Frankfurt. We configured the services (e.g. nomad-agent) on those hosts to target the brand new regional control plane and voilà, the region was ready! We just had to make our worker aware of it and release it… wait. That is more difficult than it sounds.
Adapting our workers' code to support multi-region deployments
So, we had to make the code changes in our APIs and workers to handle multi-region deployments. When users deploy an app on the platform, they push to us a deployment definition to describe the desired deployment: how much RAM should we allocate, how many instances should run, what is the image or GitHub repo to use…
First of all, at that time, a Service could only be deployed in a single region. We now wanted users to deploy the same service in different regions and potentially override some values for some regions. For example, if they want bigger instances of a service in a given region because this is where most of their users are, they should be able to.
We split the concept of deployment definition into two: regional deployment definition and deployment definition.
A deployment definition would hold the Service definition for all of the regions and all of the overrides. We added a mechanism to derive, for each region defined in a deployment definition, a regional deployment definition, which is the view of the deployment for a given region. In that way, the regional deployment definition is very close to what the original deployment definition was.
This allowed us to perform minimal changes to the existing worker. It just needs a regional deployment definition, and the right Nomad and Kuma clients:
type RegionalDeploymentDefinition struct {
Region string // e.g. "fra": the target region is Frankfurt
Scaling uint // e.g. 3: the user wants 3 instances for his service
MemMB uint // e.g. 4096: each instance gets 4 gigabytes of RAM
Image string // e.g. "koyeb/demo"
// ...
}
var nomadClients map[string]*nomad.Client
func init() {
nomadClients = map[string]*nomad.Client{
// The addresses below are resolved natively thanks to Istio mesh:
// * "nomad-api-access" is the name of the target Kubernetes service
// * "fra" is the region identifier. It is the name of the Kubernetes namespace where the Kubernetes service lives
// * "4646" is the relevant port of the Kubernetes service
"fra": nomad.NewClient("http://nomad-api-access.fra:4646"),
"was": nomad.NewClient("http://nomad-api-access.was:4646"),
// ...
}
}
// This is a simplified version of a Koyeb worker tasked to deploy a service in a region
func DeployService(ctx context.Context, req *RegionalDeploymentDefinition) error {
// Get a client to the Nomad server in the European continental Kubernetes cluster, namespace "fra"
nomadClient, ok := nomadClients[req.Region]
if !ok {
return errors.New("this region is not available")
}
// POST a new Job to Nomad server
spec := req.ToNomadSpec()
res, err := nomadClient.RegisterJob(ctx, spec)
if err != nil {
return errors.Join(err, errors.New("cannot create Nomad Job"))
}
// Do other stuff with Kuma client and Koyeb APIs
// ...
}
Sunsetting the old engine and our legacy location
With all that work done, our new region in Frankfurt was ready, compliant with our specifications.
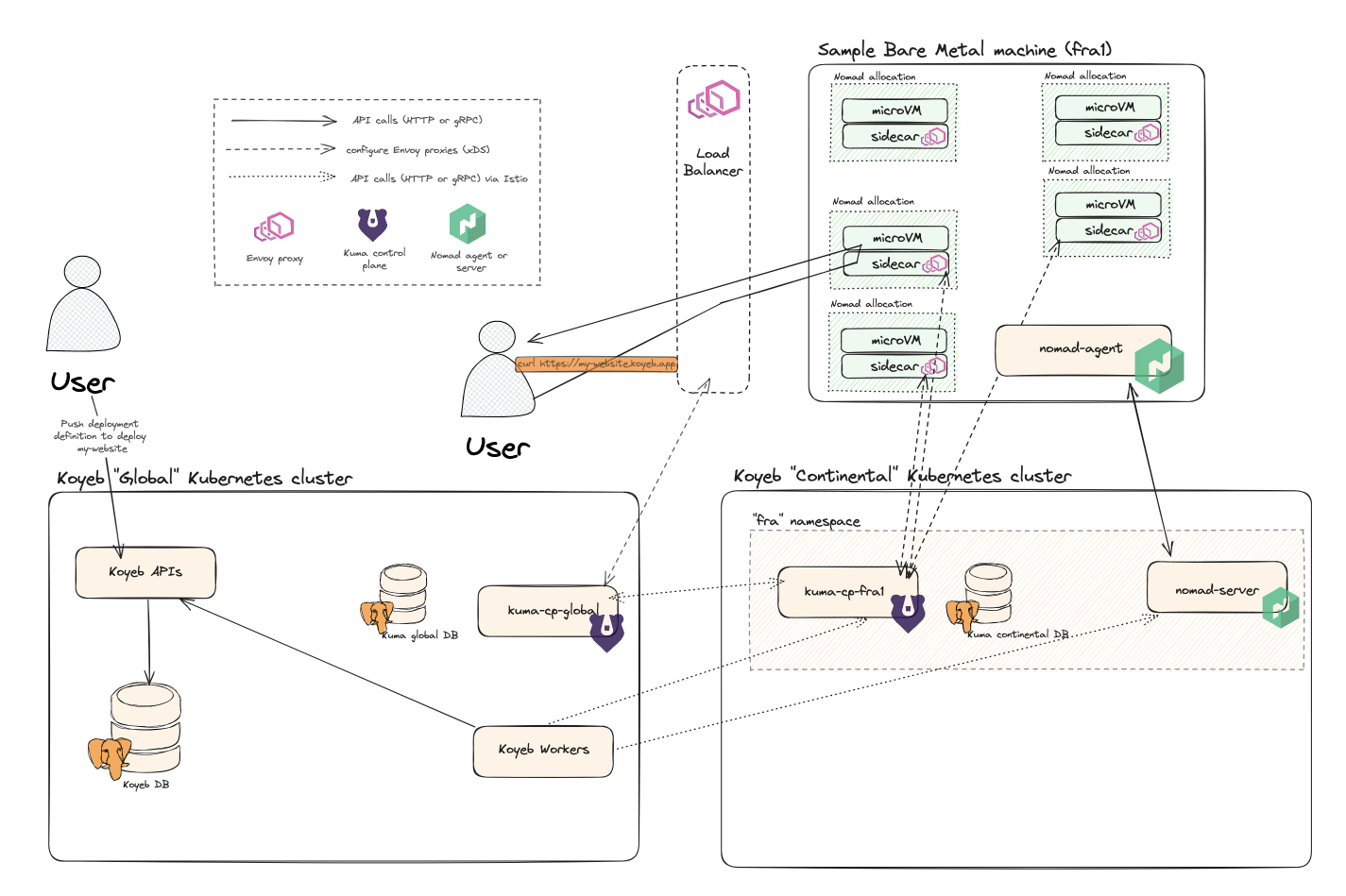 |
|---|
| How we manage apps through both Global and Continental clusters |
We ran automated tests on Frankfurt, migrated our internal accounts, and finally slowly migrated all of our users’ Services to the new fra.
At the end of December last year, every single service was officially moved to the new Frankfurt. We gave back the servers and officially bid farewell to our legacy region...
Rinse and repeat in Washington, DC: we provisioned a second region in one month
We worked for months to deploy Frankfurt. Truth is, from a user point of view, nothing much had changed: we still only offered a single location!
However, we set up pretty much all of the machinery to onboard new locations easily. And boy the architecture design paid off: we then deployed a new region in Washington in less than a month! All we needed to do was to do the same thing over again:
- Provision a new continental cluster in the US
- Provision a regional control plane in there
- Provision new bare metal machines in Washington, DC
Then, we once again ran automated tests until we slowly opened the region to our users.
Private networking & optimized global load balancing
With these two regions live, we were able to validate some features (and ship bugfixes 🤫*)* we were willing to offer for multi-region apps:
- All of your services can privately reach each other via DNS. In practice, it means that you can
curl http://my-other-service.koyeb:8080from your code and reach your other service. Traffic is transparently encrypted with mutual TLS and we take care of routing requests to the closest healthy instance where your code is running - Inbound HTTP requests take the fastest path to reach your service. Once again, in practice, it means that when someone reaches the public URL of your app, our load balancing stack will pick up the request at the closest edge location to the user and route it to the closest healthy instance where your code is running
Those are features that you get out-of-the-box when deploying an app replicated on more than one region on us - we believe that they are great for global workloads.
What's for the future?
We have a ton of ideas to improve our multi-region engine.
Port more components to continental clusters for reliability and cost management
Now, if you are attentive to details, you might have noticed that we did not mention where some of our components like our container image registry, Harbor, were in this new architecture. For example, we retrieve metrics and logs from the services running on bare metal machines to display this beautiful view:
This telemetry needs to be queryable and hence, stored somewhere. It is first crafted on bare metal machines but it needs to make its way to some database. Where is that database? For now, these kinds of components live in our global cluster.
😠 But we said that the bare metal machines should never communicate directly to the global cluster!
Correct. That is suboptimal and we know it.
As stated before, we plan on porting more and more components from our global cluster to continental clusters. It should boost performance, improve reliability and reduce our costs.
Nail the continuous deployment experience
We would like to make it a no-op for us to introduce a new region: it would be great if we could prepare end-to-end continuous deployment strategies to provision new regions, run automated tests and slowly roll them out. The same goes for rolling out configuration changes; we would love to make this frictionless and safe.
Closing thoughts: we made multi-region deployments easy!
We are so proud of our multi-region engine! The only difference when deploying an app in any of our six regions is pressing a button. (Yes, it's truly that simple).
Plus, so far, the design is keeping its promises:
- Resiliency: we deleted our whole global cluster in staging (by mistake, but still 🤫) and our staging regions kept working, acting as independent satellites, as we designed them!
- Provision new regions fast: we delivered Washington in less than 30 days a few months back. But continuous improvements to the design continued to pay off. We cooked four new regions this summer in half the time it took to ship just Washington: San Francisco, Paris, Tokyo and Singapore!
As you just read, you can now deploy your applications on our high-performance servers in six locations over the world. Test us out!
We hope you liked knowing more about some of our internals. We would love to know what you thought of this post: feel free to drop us a line on Twitter @gokoyeb or by direct message: @_nicoche @AlisdairBroshar. The same goes if you want to know more about other internals of our system, we would be happy to share more 🙂*.*