Deploy Unsloth on Koyeb for Lightning-Fast LLM Training
Introduction
Fine-tuning and training large language models (LLMs) is a resource intensive process that requires both significant computational power and time. Whether you're working on custom chatbots, domain-specific models, or research projects, the ability to efficiently fine-tune and train LLMs can speeden your AI development and release workflow.
Unsloth is an open-source framework designed to speed up and simplify LLM fine-tuning and reinforcement learning workflows. It reimplements several computationally intensive steps, such as parts of autograd and provides custom GPU kernels using Triton. These optimizations significantly reduce memory usage and improve training throughput compared to standard approaches (e.g., Flash Attention 2), allowing users to fine-tune large models more efficiently.
In this tutorial, you will learn how to deploy Unsloth on Koyeb's high-performance GPU infrastructure and run one of their pre-built Vision fine-tuning notebook.
Requirements
To successfully complete this tutorial, you will need the following:
- Basic familiarity with Python and Jupyter Notebooks
- A Koyeb account
Steps
- Deploy Unsloth server to Koyeb: Deploy your Unsloth server on Koyeb's high-performance GPU infrastructure.
- Fine-tuning with Unsloth: Understand the code in the sample notebook that fine-tunes a Llama Vision model on a radiology image-caption dataset.
- Run it on Koyeb: Execute the notebook to kick off fast model training and save your new fine-tuned weights on Koyeb.
Deploy Unsloth server to Koyeb
Koyeb makes it easy to run Unsloth in the cloud without managing servers. You can deploy the official Unsloth Docker image by visiting the one-click Unsloth deployment page: https://app.koyeb.com/one-clicks/unsloth.
This page uses the official unsloth/unsloth Docker image preconfigured with all necessary dependencies.
Click Deploy on the Koyeb Unsloth deployment page. If you’re not logged in, Koyeb will prompt you to log in or create an account.
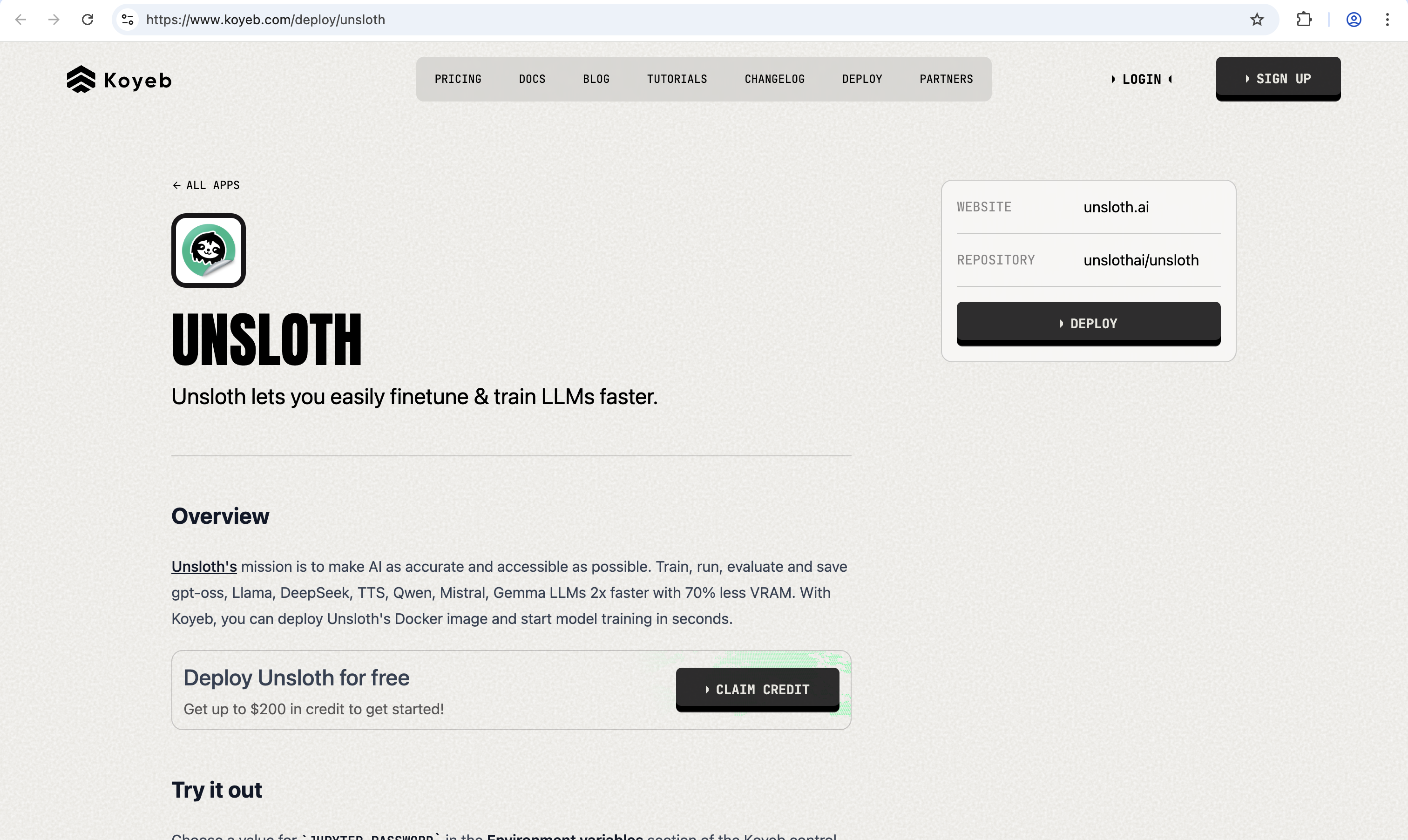
Continuing with defaults, choose a value for JUPYTER_PASSWORD in the Environment variables section of the Koyeb control panel for your Service. This password is how you access the environment through HTTPS.
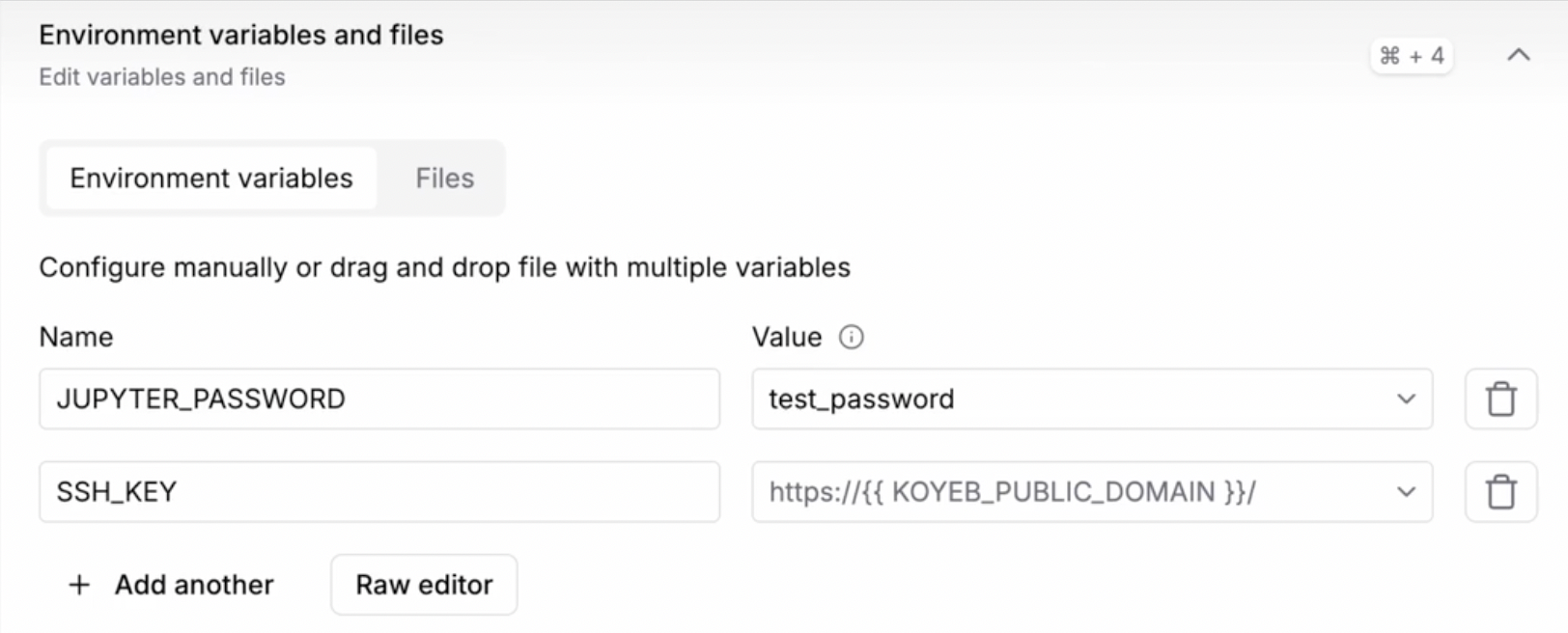
After setting these, click Deploy to start the service. Koyeb will then provision the service, set up the Docker container, and start your Unsloth instance automatically.
Once the Unsloth server is deployed, you can access the Instance using your Koyeb App URL, which is similar to: https://<YOUR_APP_NAME>-<YOUR_KOYEB_ORG>.koyeb.app.
Enter the password (i.e. the value you defined for JUPYTER_PASSWORD environment variable) to log in to the Unsloth server:

Fine-tuning with Unsloth
In this section, we take a look at the Unsloth Vision Fine-tuning notebook that fine-tunes the Llama-3.2-11B-Vision-Instruct model and adapts it to use the custom dataset prepared from the sampled version of the ROCO radiography dataset (available at unsloth/Radiology_mini on Hugging Face), which includes X-rays, CT scans, and ultrasounds with expert-written captions.
Setup
Installs and loads Unsloth, prepares a fast 4-bit vision-language model with options for efficient fine-tuning using LoRA adapters.
from unsloth import FastVisionModel
import torch
model, tokenizer = FastVisionModel.from_pretrained(
"unsloth/Llama-3.2-11B-Vision-Instruct",
load_in_4bit=True, # Use 4bit to reduce memory use
use_gradient_checkpointing="unsloth", # Memory-efficient backpropagation
)
model = FastVisionModel.get_peft_model(
model,
finetune_vision_layers = True, # False if not finetuning vision layers
finetune_language_layers = True, # False if not finetuning language layers
finetune_attention_modules = True, # False if not finetuning attention layers
finetune_mlp_modules = True, # False if not finetuning MLP layers
r = 16, # The larger, the higher the accuracy, but might overfit
lora_alpha = 16, # Recommended alpha == r at least
lora_dropout = 0,
bias = "none",
random_state = 3407,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
# target_modules = "all-linear", # Optional now! Can specify a list if needed
)
Training
Loads a medical imaging dataset, converts it into a conversation format, and fine-tunes the model with optimized settings to save GPU memory and speed up training.
from datasets import load_dataset
dataset = load_dataset("unsloth/Radiology_mini", split="train")
instruction = "You are an expert radiographer. Describe accurately what you see in this image."
def convert_to_conversation(sample):
conversation = [
{"role": "user", "content": [{"type": "text", "text": instruction}, {"type": "image", "image": sample["image"]}]},
{"role": "assistant", "content": [{"type": "text", "text": sample["caption"]}]},
]
return {"messages": conversation}
converted_dataset = [convert_to_conversation(sample) for sample in dataset]
from unsloth.trainer import UnslothVisionDataCollator
from trl import SFTTrainer, SFTConfig
FastVisionModel.for_training(model) # Enable training mode
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
data_collator=UnslothVisionDataCollator(model, tokenizer),
train_dataset=converted_dataset,
args=SFTConfig(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
warmup_steps=5,
max_steps=30,
learning_rate=2e-4,
logging_steps=1,
optim="adamw_8bit",
weight_decay=0.001,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
remove_unused_columns=False,
max_length=2048,
),
)
trainer_stats = trainer.train()
Inference & Saving
Runs the fine-tuned model to describe images, streams outputs in real time, and saves the fine-tuned adapters locally or for deployment.
FastVisionModel.for_inference(model) # Enable inference mode
image = dataset[0]["image"]
instruction = "You are an expert radiographer. Describe accurately what you see in this image."
messages = [
{"role": "user", "content": [{"type": "image", "image": image}, {"type": "text", "text": instruction}]}
]
input_text = tokenizer.apply_chat_template(messages, add_generation_prompt=True)
inputs = tokenizer(image, input_text, add_special_tokens=False, return_tensors="pt").to("cuda")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer, skip_prompt=True)
_ = model.generate(
**inputs,
streamer=text_streamer,
max_new_tokens=128,
use_cache=True,
temperature=1.5,
min_p=0.1,
)
model.save_pretrained("lora_model") # Save LoRA adapters locally
tokenizer.save_pretrained("lora_model")
Run it on Koyeb
Now let’s see the fine-tuning in action. We’ll use the previously deployed Unsloth instance, which already has the dataset and the files prepared and ready for training.
Run the notebook titled "Llama3.2_(11B)-Vision.ipynb", and it will first start downloading the base model:

Once the dataset is processed, the fine-tuning begins:
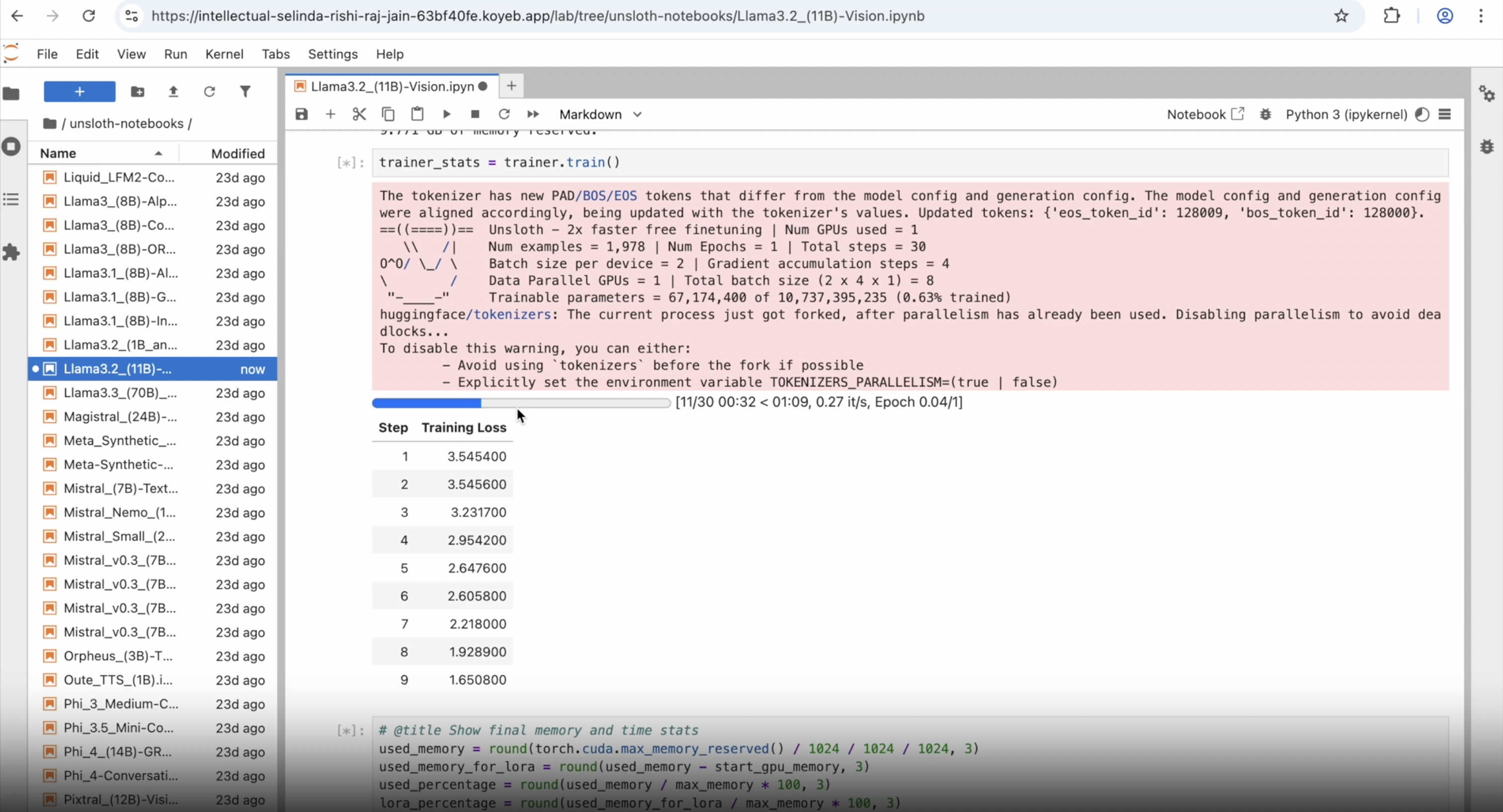
After a few minutes, the training completes and the custom model is automatically saved locally (by default).
To push your fine-tuned model and processor to Hugging Face, make sure you define your Hugging Face username and access token. This ensures the model is uploaded to the correct account.
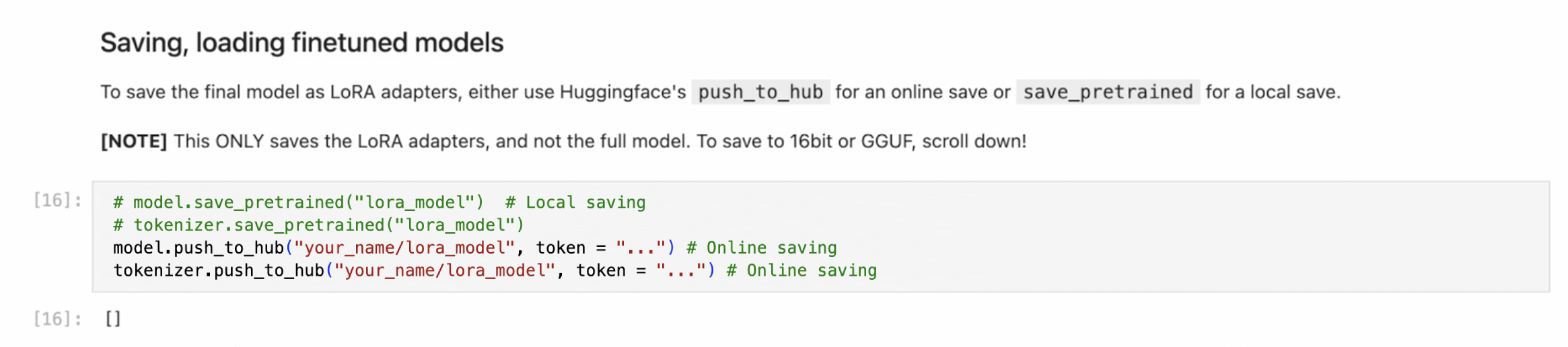
You have successfully fine-tuned a custom Llama-3.2-11B-Vision-Instruct model and saved it for repeated AI inference.
The process is very cost-effective: the entire dataset preparation and fine-tuning took nearly 4 minutes and cost only $1 using the default NVIDIA L40S GPU. You can get started by signing up on Koyeb and claiming $200 in credits.
Conclusion
This guide covered deploying Unsloth on Koyeb's GPU infrastructure and fine-tuning a Llama Vision model on a radiology dataset. With Koyeb's one-click deployment, you can get an Unsloth server running in very few minutes without managing infrastructure on your own. The setup includes model configuration with LoRA adapters, dataset preparation, training execution, and saving fine-tuned weights. The entire workflow is optimized for speed and cost-efficiency, making it straightforward to iterate on custom LLM fine-tuning projects.
What's next?
- Take your project to the next level by fine-tuning a Whisper TTS model with Unsloth and deploying it to Koyeb
- Try a different fine-tuning method, like using Axolotl to fine-tune Llama 3 on Koyeb serverless GPUs
- Share what you build! We love to see what developers build on Koyeb. Share on the Koyeb Community

