Deploy a Cron Job to Deliver the Latest Hacker News Stories through WhatsApp
Introduction
Have you ever had a fellow technical friend who always seems to be up on the latest news? It can be tough to keep up with everything that's going on in the tech world. Inspired by everyone's techie friend, this tutorial shows you how you can create your own technical companion that makes sure you always know what's going on.
In this tutorial, you'll create a cron job that runs once a day, informing you of the top Hacker News posts through WhatsApp using Supercronic, the Hacker News API, OpenAI's open source LLM gpt-oss-20b hosted on Koyeb, and Twilio.
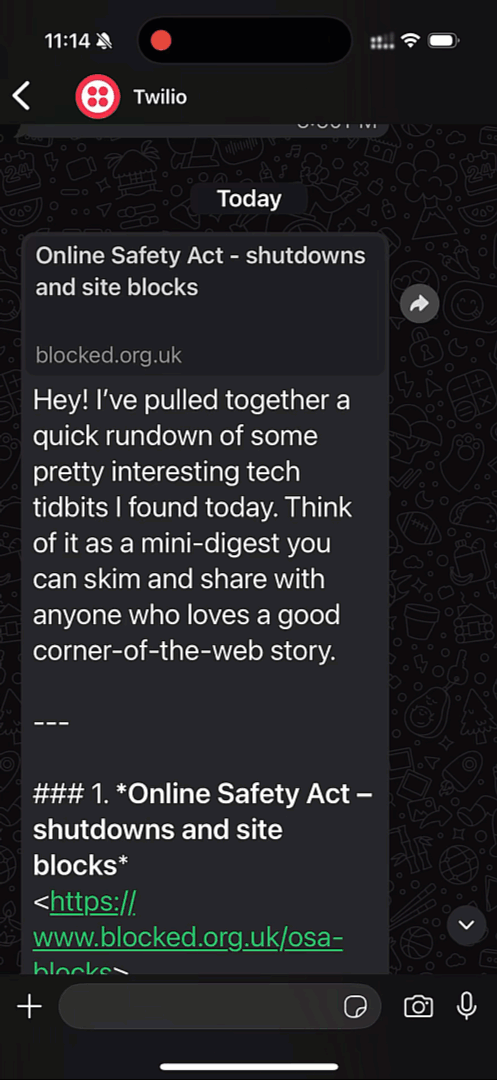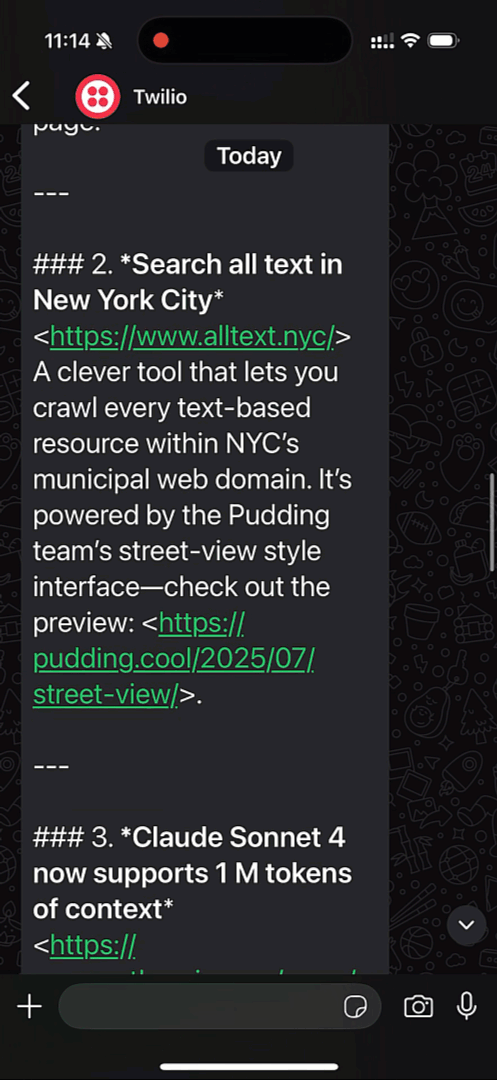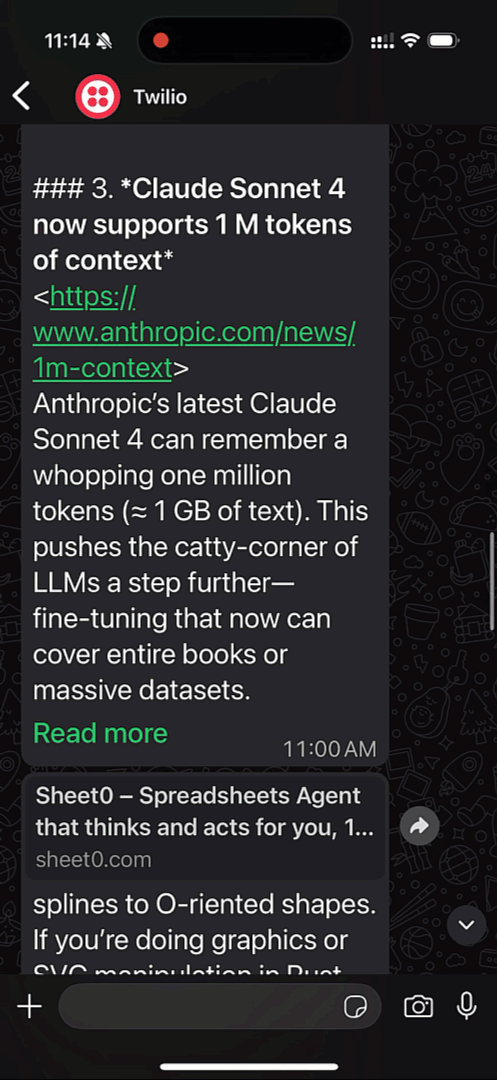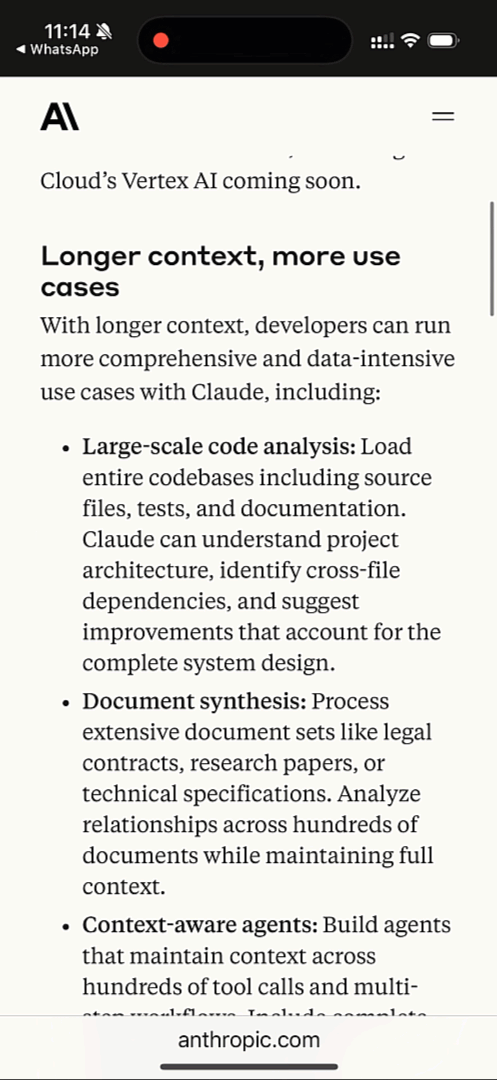
- Supercronic is designed to make it easy to run cron jobs in containers.
- The Hacker News API makes public Hacker News data available in near real time using Firebase.
- OpenAI's new open source model, gpt-oss-20b, is lightweight and well-suited for a task like conversing about tech news stories.
- Twilio's products encompass multiple communications solutions, including straightforward APIs for sending messages through WhatsApp. With the SMS, voice, and email options Twilio offers, this demo can be easily extended to other communication modalities.
- Koyeb provides the infrastruction to deploy gpt-oss-20b on GPU and the cron job on CPU with the click of a button.
Requirements
To follow along with this guide, you will need to create accounts with the following services. Both services offer an option to start for free:
- Koyeb: We use Koyeb to deploy and run
gpt-oss-20band the cron application. - Twilio: We use Twilio to send the summary as WhatsApp messages.
Steps
To build and deploy our cron job, we'll take the following steps:
- Deploy gpt-oss-20b to Koyeb using one-click deploy.
- Set up Twilio to send WhatsApp messages.
- Deploy the cron job app using Koyeb one-click deploy.
- Add the environment variables.
- Examine the code.
Deploy gpt-oss-20b
OpenAI's introduced their first open source llm offerings in the gpt-oss models. The gpt-oss-20b model has sufficient reasoning power for the lightweight use case of acting as a friend who tells you tech news.
Use the following button to deploy gpt-oss-20b on an NVIDIA A100 running on the Koyeb platform:

Set up Twilio
To get the required credentials for Twilio, sign up and activate the Twilio Sandbox.
Walk through all the steps of the Try WhatsApp sandbox, including sending a templated message and replying from your WhatsApp number.
To prevent spam and abuse, Twilio requires you to send a Business-Initiated message that the user must then reply to in order for you to send freeform messages for 24 hours. You can find the details on Twilio's help site.
The sandbox also gives you the two credential values you need for Twilio: the accound_sid and the auth_token. Take note of these values for the next steps of the tutorial.
Deploy the application
To deploy your cron job, first click the following button:
This brings you to the configuration page for the Service where you will add details before proceeding.
Add environment variables
Before clicking Deploy, click Environment variables and files and add the following five environment variables:
- GPT_OSS_20B_API_URL: the URL where you just deployed gpt-oss-20b. You can find this by selecting your Service in the Koyeb console and clicking the Copy button next to the Public URL.
- TWILIO_AUTH_TOKEN: the
auth_tokenvalue from the Twilio Sandbox. - TWILIO_SID: the
accound_sidvalue from the Twilio Sandbox. - WHATSAPP_FROM: the phone number found in the Twilio Sandbox.
- WHATSAPP_TO: your WhatsApp phone number where you want to receive messages.
Alternatively, you can provide a config file or set the envars using the Koyeb CLI. See the documentation for details.
Examine the code
To check out the code for the cron job, clone the GitHub repo and open the code in the IDE of your choice. The project has the following file structure:
.dockerignore
app.py # The main entry point of the Python app
crontab # The interval at which the cron job runs
Dockerfile
hacker_news.py # Interacts with the Hacker News API to pull the latest popular stories
LICENSE
llm.py # Interacts with gpt-oss-20b to create a conversational interaction
README.md
requirements.txt
script.sh # Triggered by the cron job. Runs the Python app
Using Supercronic
In the app's Dockerfile, we find all the components that download and set up Supercronic:
FROM python:3.11-alpine
# Install Supercronic
RUN apk add --no-cache bash curl \
&& curl -fsSLO "https://github.com/aptible/supercronic/releases/latest/download/supercronic-linux-amd64" \
&& chmod +x supercronic-linux-amd64 \
&& mv supercronic-linux-amd64 /usr/bin/supercronic \
&& /usr/bin/supercronic -version
WORKDIR /app
# Copy crontab to a fixed path
COPY crontab /etc/crontab
RUN chmod 0644 /etc/crontab
# Get the required pip packages
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy python app files
COPY ["*.py", "./"]
# Copy script
COPY script.sh ./script.sh
RUN chmod +x ./script.sh
# Use ENTRYPOINT + CMD
ENTRYPOINT ["/usr/bin/supercronic"]
CMD ["/etc/crontab"]
Here we download and install the Supercronic package for amd64 and grant access to our crontab and script. You can find the latest intructions for downloading Supercronic for various builds in the Supercronic release docs.
The crontab file dictates the interval at which our app will run:
# Check Hacker News every day at 9:00 am
0 9 * * * /app/script.sh
# Alternatively, enable every 5 minutes for testing
# */5 * * * * /app/script.sh
There is an option included to run every 5 minutes for testing, which you can update if you choose to clone and modify the repo.
The crontab runs script.sh, which kicks off our Python app:
#!/bin/bash
set -e
echo "[$(date)] Running my function..."
python /app/app.py
Using the Hacker News API
In the hacker_news.py file, you can find the code for interacting with the Hacker News API:
This class contains three main functions:
get_def_top_storiesqueries the 10 latest top stories from Hacker News and returns a list of story IDs. This can include links, comments, and job postings:
# Get an array of IDs of the top stories from Hacker News
def get_top_stories(self):
order_by_value = quote('$key', safe='$')
try:
response = requests.get(f'{self.hn_base_url}topstories{self.endpoint_suffix}/?limitToFirst={10}&orderBy="{order_by_value}"')
response.raise_for_status()
data = response.json()
return data
except requests.exceptions.RequestException as e:
print('Error calling Top Stores API:', e)
get_story_by_idpulls the details of a story given its story ID.
# Get story information for a given story ID
def get_story_by_id(self, item_id: str):
try:
response = requests.get(f'{self.hn_base_url}item/{item_id}{self.endpoint_suffix}')
response.raise_for_status()
data = response.json()
return data
except requests.exceptions.RequestException as e:
print('Error calling Item ID API:', e)
load_top_stories_concurrentcombines the two functions, allowing you to concurrently query story details on all 10 top stories, and returning them in an array:
# Build array of top stories
def load_top_stories_concurrent(self):
top_story_ids = self.get_top_stories()
results = []
with ThreadPoolExecutor(max_workers=5) as executor:
future_to_id = {executor.submit(self.get_story_by_id, str(story_id)): story_id for story_id in top_story_ids}
for future in as_completed(future_to_id):
story_id = future_to_id[future]
try:
story_data = future.result()
if story_data:
story = {
'title': story_data.get('title', None),
'text': story_data.get('text', None),
'url': story_data.get('url', None)
}
results.append(story)
except Exception as e:
print(f'Exception fetching story {story_id}: {e}')
return results
Calling gpt-oss-20b to summarize
In the llm.py file, you can find the code for interacting with the model we deployed earlier.
Note: At the time of writing this, there is a bug in serving gpt-oss on vllm when using the Chat Completions API, so instead, Completions is used.
The summarize_hn function gives the story array to gpt-oss to deliver the information in a more friendly, conversational manner:
# Uses the completions function to create a response
def summarize_hn(self, formatted_input: str, temperature: float = 1.0, max_tokens: int = 500, role: str = 'user'):
instructions = (
'You are ChatGPT. Given a set of stories, create a summary message explaining the stories as though you were speaking to a friend.'
'Include the links to all the stories if present, or just the info from the text if present.'
)
tokenizer = AutoTokenizer.from_pretrained('openai/gpt-oss-20b', trust_remote_code=True)
# Send a request to the OpenAI API and return the response.
if not isinstance(formatted_input, str):
formatted_input = formatted_input.to_string()
try:
messages=[{'role': 'system', 'content': instructions},{'role': role, 'content': formatted_input}]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
response = self.client.completions.create(
prompt=prompt,
model=f'/models/{self.model}',
max_tokens=max_tokens,
temperature=temperature
)
if response.choices:
chat_response = response.choices[0].text
match = re.search(r'final(.*)', chat_response, re.DOTALL)
# Remove newlines
final_result = match.group(1).replace(r'\\n', ' ').replace('\\', '').strip()
# Remove markdown formatting from URLs
final_result = re.sub(r'\[([^\]]+)\]\((https?://[^\)]+)\)', r'\1: \2', final_result)
return final_result if final_result else None
except Exception as e:
print(f'Request failed: {e}')
return None
This class could easily be extended to handle conversation with the LLM, allowing you to ask for additional details about individual stories through WhatsApp.
Delivering WhatsApp messages through Twilio
In app.py, the data gathered from Hacker News gets passed to the LLM for processing:
client = Client(account_sid, auth_token)
llm = GptOpenAi()
hacker_news = HackerNews()
# Get the ten top stories
top_stories = hacker_news.load_top_stories_concurrent()
# Have gpt-oss-20b summarize the stories
top_summary = llm.summarize_hn(f'{top_stories}', max_tokens=4000)
Finally, the results are split into chunks that fit the character limits for WhatsApp and Twilio, and then these chunks are sent to your number:
# Send messages to your WhatsApp number
def send_whatsapp_message_in_chunks(body, chunk_size=1600):
# Split gpt-oss-20b response into 1600 char chunks to meet the delivery limits of WhatsApp with Twilio
part_num = 1
while body:
if len(body) > chunk_size:
split_point = body.rfind(' ', 0, chunk_size)
if split_point == -1:
split_point = chunk_size
else:
split_point = len(body) # final chunk size or smaller
part = body[:split_point]
body = body[split_point:].lstrip()
# Send the chunk
message = client.messages.create(
to=f'whatsapp:{whatsapp_to}',
from_=f'whatsapp:{whatsapp_from}',
body=part
)
print(f'Sent part {part_num} SID: {message.sid}')
part_num += 1
messages = send_whatsapp_message_in_chunks(top_summary)
Conclusion
In this tutorial, we deployed a cron job and used it to periodically interact with multiple services: the Hacker News API, OpenAI's gpt-oss-20b, and WhatsApp through Twilio.
We used Koyeb to deploy two very difference Services—an LLM on GPU and a cron job on CPU—showing the flexibility and extensibility of the platform.
With this project, now you can become that friend who always knows the latest tech news! To keep the conversation with your tech friend alive, be sure to respond at least once every 24 hours on WhatsApp as required by Twilio.

