Using Dia 1.6B to Build a Text-to-Speech Application on Serverless GPUs
Text-to-speech (TTS) models are a part of many modern AI applications, enabling natural interactions in virtual assistants, audiobook generation and accessibility tools. Despite their transformative impact, these models can be resource-intensive, leading to high latency, increased operational costs, and scalability challenges. Therefore, optimizing TTS models is essential for efficient, cost-effective deployment.
In this tutorial, we’ll walk you through building a full-stack TTS application powered by Dia-1.6B model, developed by Nari Labs. It is a TTS model known for its natural voice modulation and expressive intonation. Its capabilities make it a good model for creating lifelike speech.
You’ll learn how to set up a FastAPI backend, build a Svelte-based frontend, and deploy both components on Koyeb. To try the app yourself, you can easily deploy it on Koyeb using the one-click deploy buttons below:
Backend Deployment

Frontend Deployment
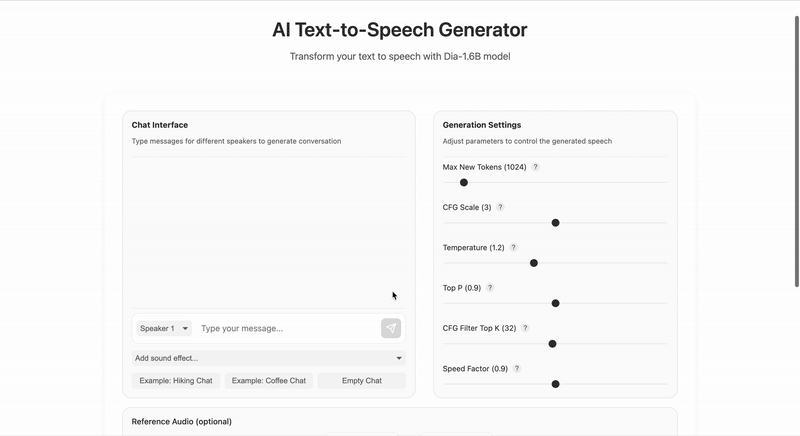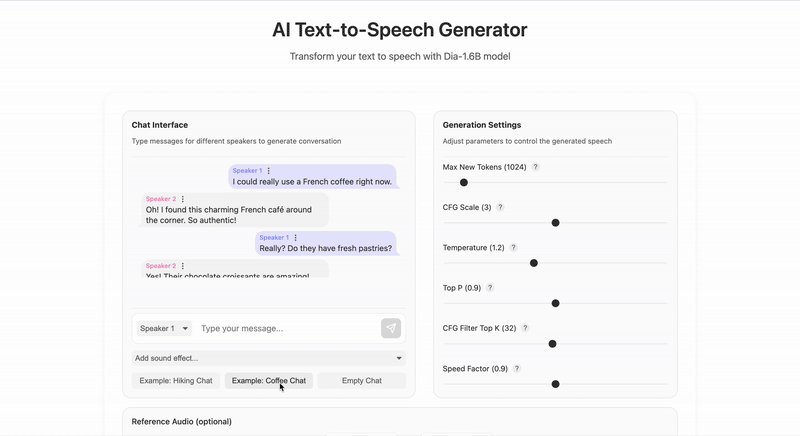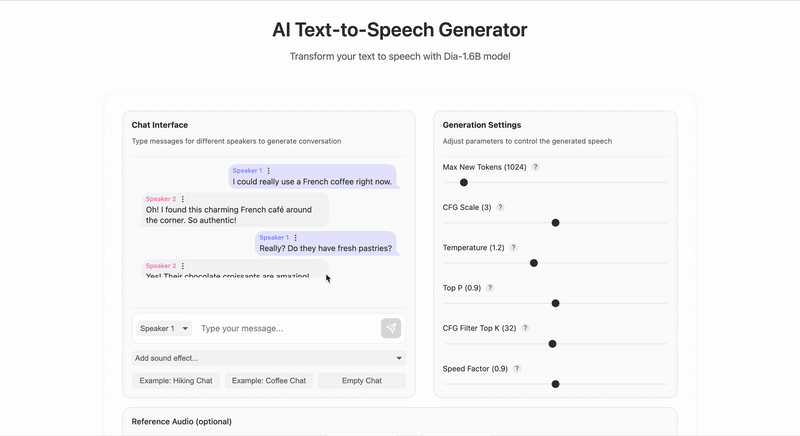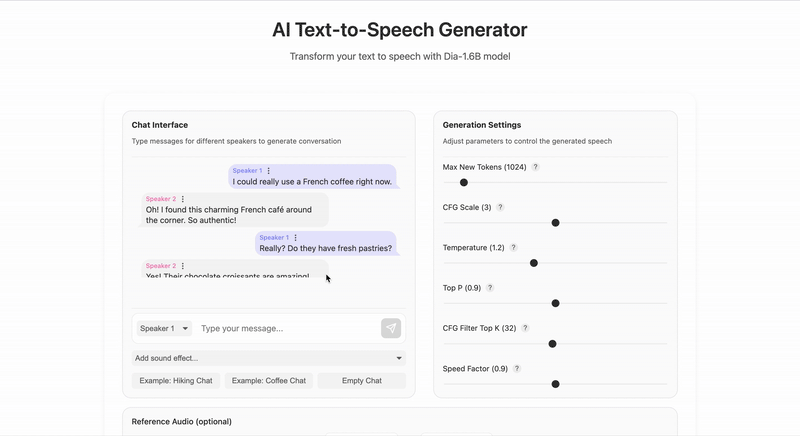
Example Prompt
Here's an example of how you can use the Dia-1.6B model to generate text-to-speech audio. This example uses the default settings, except for New Max Tokens, which I set to 2020.
- Speaker 1: I could really use a French coffee right now.
- Speaker 2: Oh! I found this charming French café around the corner. So authentic!
- Speaker 1: Really? Do they have fresh pastries?
- Speaker 2: Yes! Their chocolate croissants are amazing! And the owner is from Paris. (humming)
Listen to the generated audio on Youtube 🔊
Requirements
To successfully follow and complete this guide, you need:
- A Koyeb account
- A GitHub account
- Python 3.6 - 3.10 installed on your local development environment
- Node.js 16+ installed on your local development environment
- pnpm and uv (Python package installer) installed on your local development environment
Steps
To successfully build and deploy the text-to-speech application using Dia 1.6B to Koyeb, you need to follow these steps:
Architecture
Before taking a closer look at the project, it consists of two main directories:
backend/: Contains the FastAPI server and Dia model implementation.frontend/: Contains the Svelte frontend application.
Backend Setup
Start by cloning this repository to your local machine and navigating to the backend directory:
git clone <https://github.com/koyeb/example-dia-text-to-voice.git>
cd text_to_voice/backend uv sync
or you can start from scratch by running
mkdir dia-text-to-speech
cd dia-text-to-speech
uv init backend
cd backend
uv add fastapi[standard] pydantic soundfile torch transformers[torch]
Let's take a closer look at the backend code, especially the main.py file. If you started from scratch you can add the code snippets into the main.py file in your project in the same order as they appear here.
Import all necessary Python libraries for API handling, audio processing, model operations, and logging. The Dia model is loaded from Hugging Face Transformers.
import logging
from contextlib import asynccontextmanager
from fastapi import FastAPI, HTTPException
from fastapi.middleware.cors import CORSMiddleware
from fastapi.responses import FileResponse
from pydantic import BaseModel
import time
from typing import Optional, List
from pathlib import Path
import torch
from transformers import AutoProcessor, DiaForConditionalGeneration
from utils import process_audio_prompt
Next, set up structured logging to help with debugging and monitoring the application:
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s",
handlers=[logging.StreamHandler()],
)
logger = logging.getLogger(__name__)
Ensure that the audio_files and upload_files directories exist for storing generated audio files and uploaded files. This is important for managing the application's file outputs and uploads.
AUDIO_DIR = Path("audio_files")
AUDIO_DIR.mkdir(exist_ok=True)
UPLOADS_DIR = Path("upload_files")
UPLOADS_DIR.mkdir(exist_ok=True)
Check if a CUDA-enabled GPU is available and set the computation device to "cuda" if available, otherwise use "cpu".
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
logger.info(f"Using DEVICE: {DEVICE}")
Audio Prompt Processing Utility
Import the process_audio_prompt from utils.py. It takes an audio prompt, validates and processes it (normalization, mono conversion), and saves it as a temporary file, returning the file path for use in further processing. If the audio is empty or silent, it returns None.
If you started from scratch, create a utils.py file. It provides utility functions for audio processing.
import logging
import numpy as np
import tempfile
import soundfile as sf
from fastapi import HTTPException
from typing import Optional, List
from pydantic import BaseModel
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s",
handlers=[logging.StreamHandler()],
)
logger = logging.getLogger(__name__)
def is_audio_empty_or_silent(audio_data: np.ndarray) -> bool:
"""Check if audio data is empty, None, or silent."""
return audio_data is None or audio_data.size == 0 or audio_data.max() == 0
def normalize_audio_dtype(audio_data: np.ndarray) -> np.ndarray:
"""Convert audio data to float32 format."""
if np.issubdtype(audio_data.dtype, np.integer):
max_val = np.iinfo(audio_data.dtype).max
return audio_data.astype(np.float32) / max_val
elif not np.issubdtype(audio_data.dtype, np.floating):
logger.warning(f"Unsupported audio prompt dtype {audio_data.dtype}, attempting conversion.")
try:
return audio_data.astype(np.float32)
except Exception as conv_e:
raise HTTPException(status_code=400, detail=f"Failed to convert audio prompt to float32: {conv_e}")
return audio_data
def convert_to_mono(audio_data: np.ndarray) -> np.ndarray:
"""Convert multi-channel audio to mono."""
if audio_data.ndim > 1:
if audio_data.shape[0] == 2:
audio_data = np.mean(audio_data, axis=0)
elif audio_data.shape[1] == 2:
audio_data = np.mean(audio_data, axis=1)
else:
logger.warning(f"Audio prompt has unexpected shape {audio_data.shape}, taking first channel/axis.")
audio_data = audio_data[0] if audio_data.shape[0] < audio_data.shape[1] else audio_data[:, 0]
audio_data = np.ascontiguousarray(audio_data)
return audio_data
def save_audio_to_temp_file(audio_data: np.ndarray, sample_rate: int) -> str:
"""Save audio data to a temporary WAV file and return the file path."""
with tempfile.NamedTemporaryFile(mode="wb", suffix=".wav", delete=False) as f_audio:
temp_path = f_audio.name
try:
sf.write(temp_path, audio_data, sample_rate, subtype="FLOAT")
logger.info(f"Created temporary audio prompt file: {temp_path} (sr: {sample_rate}, shape: {audio_data.shape}, max: {audio_data.max():.3f}, min: {audio_data.min():.3f})")
return temp_path
except Exception as write_e:
logger.error(f"Error writing temporary audio file: {write_e}")
raise HTTPException(status_code=400, detail=f"Failed to save audio prompt: {write_e}")
def process_audio_prompt(audio_prompt) -> Optional[str]:
"""
Process the audio prompt input and return the path to the temporary audio file.
Returns None if the audio is empty or silent.
"""
audio_data = np.array(audio_prompt.audio_data, dtype=np.float32)
sample_rate = audio_prompt.sample_rate
if is_audio_empty_or_silent(audio_data):
logger.warning("Audio prompt seems empty or silent, ignoring prompt.")
return None
logger.info(f"Processing audio prompt: shape={audio_data.shape}, sample_rate={sample_rate}, dtype={audio_data.dtype}")
audio_data = normalize_audio_dtype(audio_data)
audio_data = convert_to_mono(audio_data)
return save_audio_to_temp_file(audio_data, sample_rate)
Let's take a look at what it includes:
- Logging setup for consistent debug and info messages
- Audio validation and processing helpers:
is_audio_empty_or_silent: Checks if audio data is missing, empty, or silent.normalize_audio_dtype: Ensures audio data is in float32 format, converting from integers or other types if needed.convert_to_mono: Converts multi-channel (stereo) audio to mono by averaging channels.save_audio_to_temp_file: Saves processed audio data to a temporary WAV file and returns its path.process_audio_prompt: Main function that validates, normalizes, converts, and saves an audio prompt, returning the file path or None if the audio is empty.
These utilities are used to prepare audio prompts for the text-to-speech model, ensuring the input is valid and in the correct format.
ModelManager Class
Continue with the main.py. This class in main.py is responsible for managing the Dia model lifecycle, including loading and unloading the model and providing access to it.
Set up the computation device (CPU or GPU) and choose the appropriate data type for the model:
- Use float32 if running on CPU.
- Use float16 if running on GPU (to save memory).
Also, set up the model manager attributes:
- Set
self.modelto None, no model loaded initially. - Set
self.processorto None, no processor loaded initially. - Set
self.model_idto"nari-labs/Dia-1.6B-0626", specifies the Hugging Face model to use.
class ModelManager:
"""Manages the loading, unloading and access to the Dia model and processor using Hugging Face Transformers."""
def __init__(self):
self.device = DEVICE
self.dtype_map = {
"cpu": "float32",
"cuda": "float16",
}
self.model = None
self.processor = None
self.model_id = "nari-labs/Dia-1.6B-0626"
Download and load the Dia model and processor from Hugging Face:
- Get the appropriate data type for the current device (CPU or GPU).
- Load the
AutoProcessorfrom the specified model ID. - Load the
DiaForConditionalGenerationmodel with the specified data type and device mapping. - Log the loading process and handle any errors that occur.
def load_model(self):
"""Load the Dia model and processor with appropriate configuration using Hugging Face Transformers."""
try:
dtype = self.dtype_map.get(self.device, torch.float16)
logger.info(f"Loading model and processor with {dtype} on {self.device}")
self.processor = AutoProcessor.from_pretrained(self.model_id)
self.model = DiaForConditionalGeneration.from_pretrained(
self.model_id,
torch_dtype=dtype,
device_map=self.device
)
logger.info("Model and processor loaded successfully")
except Exception as e:
logger.error(f"Error loading model or processor: {e}")
raise
Release the model from memory and ensure GPU memory is properly freed.
def unload_model(self):
"""Cleanup method to properly unload the model."""
try:
del self.model
if torch.cuda.is_available():
torch.cuda.empty_cache()
except Exception as e:
logger.error(f"Error unloading model: {e}")
Check if the model is loaded. If the model is not loaded, raise aRuntimeError instructing the user to call load_model() first. If the model is loaded, return the model instances.
def get_model(self):
if self.model is None:
raise RuntimeError("Model not loaded. Call load_model() first.")
return self.model
Return the loaded processor instance. If the processor is not loaded, it raises a RuntimeError instructing the user to call load_model() first. If the processor is loaded, return the processor instance.
def get_processor(self):
if self.processor is None:
raise RuntimeError("Processor not loaded. Call load_model() first.")
return self.processor
model_manager = ModelManager()
API Setup and configuration
With the model and audio prompt processing in place, the next step is to set up the FastAPI backend that powers the text-to-speech service.
This includes defining the request models, configuring the application lifecycle (loading/unloading the model), enabling frontend access via CORS, and adding a health check endpoint for easy diagnostics.
Create an AudioPrompt model to represent audio input (with sample rate and audio data). Create also a GenerateRequest model to represent the request body for audio generation, including text, audio prompt, and generation parameters. Note that speed_factor is defined but not currently used in the generation process.
class AudioPrompt(BaseModel):
sample_rate: int
audio_data: List[float]
class GenerateRequest(BaseModel):
text_input: str
audio_prompt_input: Optional[AudioPrompt] = None
max_new_tokens: int = 1024
cfg_scale: float = 3.0
temperature: float = 1.3
top_p: float = 0.95
cfg_filter_top_k: int = 35
speed_factor: float = 0.94
Define a lifespan function to handle startup and shutdown events:
- On startup: Log a message and load the Dia model.
- On shutdown: Log a message and unload the Dia model.
@asynccontextmanager
async def lifespan(_: FastAPI):
"""Handle model lifecycle during application startup and shutdown."""
logger.info("Starting up application...")
model_manager.load_model()
yield
logger.info("Shutting down application...")
model_manager.unload_model()
logger.info("Application shut down successfully")
Instantiate the FastAPI app with a title, description, version, and the custom lifespan handler.
app = FastAPI(
title="Dia Text-to-Voice API",
description="API for generating voice using Dia model",
version="1.0.0",
lifespan=lifespan,
)
Add CORS middleware to allow requests from specific frontend URLs and localhost for development. Enable credentials, all HTTP methods, and all headers.
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
Define a /api/health GET endpoint that returns a simple status message to confirm the backend is running.
# Health check endpoint to verify the backend is runnin
@app.get("/api/health")
async def health_check():
return {"status": "ok", "message": "Backend is running"}
Main Generation Endpoint and Input Validation
The /api/generate endpoint takes in user input (text and an optional voice prompt), runs inference using the Dia model, and returns a synthesized voice clip.
It handles everything from input validation and audio prompt processing to model inference, speed adjustment, audio formatting, and final file response.
Check if the text_input field in the request is empty or only whitespace. If invalid, raise an HTTP 400 error.
@app.post("/api/generate")
async def run_inference(request: GenerateRequest):
"""
Runs Dia inference using the model and processor from model_manager and provided inputs.
Uses temporary files for audio prompt compatibility with inference.generate.
"""
if not request.text_input or request.text_input.isspace():
raise HTTPException(status_code=400, detail="Text input cannot be empty.")
Initialize variables for temporary text and audio prompt files (if needed). Set the output file path for the generated audio, using a timestamped filename.
output_filepath = AUDIO_DIR / f"{int(time.time())}.wav"
If an audio prompt is included in the request, process it (e.g., save or convert) for use in generation.
try:
prompt_path_for_generate = None
if request.audio_prompt_input is not None:
prompt_path_for_generate = process_audio_prompt(request.audio_prompt_input)
Retrieve the loaded Dia model and processor from the model manager.
model = model_manager.get_model()
processor = model_manager.get_processor()
Next, add the following:
start_time = time.time()
processor_inputs = processor(
text=[request.text_input],
padding=True,
return_tensors="pt"
)
processor_inputs = {k: v.to(model.device) for k, v in processor_inputs.items()}
if prompt_path_for_generate is not None:
processor_inputs["audio_prompt"] = prompt_path_for_generate
with torch.inference_mode():
logger.info(f"Starting generation with audio prompt: {prompt_path_for_generate}")
outputs = model.generate(
**processor_inputs,
max_new_tokens=request.max_new_tokens,
guidance_scale=request.cfg_scale,
temperature=request.temperature,
top_p=request.top_p,
top_k=request.cfg_filter_top_k
)
logger.info(f"Generation completed. Output shape: {outputs.shape if hasattr(outputs, 'shape') else type(outputs)}")
decoded = processor.batch_decode(outputs)
processor.save_audio(decoded, str(output_filepath))
logger.info(f"Audio saved to {output_filepath}")
end_time = time.time()
logger.info(f"Generation finished in {end_time - start_time:.2f} seconds.")
Here's a breakdown of the code:
- Start a timer for performance logging
- Process the text input using the processor to create tensor inputs
- Move the inputs to the model's device. Add the audio prompt to the inputs if provided
- Use
torch.inference_mode()for efficient inference - Call the model's
generatemethod with all relevant parameters - Decode the outputs using the processor and save the audio to a file using the processor's
save_audiomethod - Log the output shape and time taken
Next, return the generated audio file as a response, with appropriate media type and filename.
return FileResponse(
path=str(output_filepath),
media_type="audio/wav",
filename=output_filepath.name
)
Log any exceptions that occur. If the error is an HTTPException, re-raise it. Otherwise, return an HTTP 500 error with the error message. Note that this implementation doesn't include a finally block for cleanup.
except Exception as e:
logger.error(f"Error during inference: {e}")
if isinstance(e, HTTPException):
raise e
raise HTTPException(status_code=500, detail=str(e))
Write the processed audio to a WAV file at the output path. Log the file save operation.
sf.write(str(output_filepath), output_audio_np, output_sr)
logger.info(f"Audio saved to {output_filepath}")
Return the generated audio file as a response, with the appropriate media type and filename.
return FileResponse(
path=str(output_filepath),
media_type="audio/wav",
filename=output_filepath.name
)
Log any exceptions that occur. If the error is an HTTPException, re-raise it. Otherwise, return an HTTP 500 error with the error message.
except Exception as e:
logger.error(f"Error during inference: {e}")
if isinstance(e, HTTPException):
raise e
raise HTTPException(status_code=500, detail=str(e))
You can optimize the model for faster inference using Pruna AI. Follow this tutorial about using Pruna to speed up your inference speeds for guidance.
To view the entire backend code, check out the GitHub repository.
Frontend Setup
The frontend isn't in as much focus as the backend in this tutorial. You can play around and try out the frontend to find a layout and features that you like.
It uses SvelteKit with a modular component architecture:
Core Components:
ChatInterface.svelte: Manages message display, input handling, and speaker selection.GenerationSettings.svelte: Provides controls for AI model parameters with tooltips.SoundEffectsPanel.svelte: Allows sound effect selection and includes example dialogues.AudioControls.svelte: Handles audio recording, file uploads, and playback.GenerationButton.svelte: Facilitates TTS generation and communicates with the backend. Remember to change the URL on line 123 if your deploying it your self.AudioOutput.svelte: Displays playback and download options for generated audio.home.svelte: Main landing page component that orchestrates the text-to-voice interface.
To try the frontend, navigate to the frontend directory:
cd frontend
Install dependencies:
pnpm install
Start the development server:
pnpm run dev
To checkout the frontend code, visit the GitHub repository.
Deploy the Application to Koyeb
You can deploy the app using the Koyeb control panel or the CLI.
In this tutorial, we will leverage the CLI to deploy. Here are the deployment commands:
Backend:
koyeb deploy . example-dia-text-to-speech/backend \
--instance-type gpu-nvidia-A100 \
--region na \
--type web \
--port 8000:http \
--archive-builder
Frontend:
koyeb deploy . example-dia-text-to-speech/frontend \
--instance-type nano \
--region na \
--type web \
--port 4173:http \
--archive-builder
After a couple of minutes your services will be deployed. You can access it by navigating to the Public URL.
Here's a quick demo of the application in action:
Conclusion
This tutorial has guided you through setting up the backend with FastAPI, creating an interactive frontend with SvelteKit, and deploying the application on Koyeb.
You can now explore further customization, optimize the model for better performance, or expand the application's features. Here are some examples:
- Audio Caching System: Implement a caching mechanism that stores generated audio files using a hashing function of the request parameters. This prevents regenerating identical content and significantly improves response times for repeated requests.
- Voice Cloning Gallery: Create a library of pre-recorded voices with different accents and styles. Implement voice preset selection with audio samples, allowing users to choose from various voice options without needing to upload reference audio.
To explore more, go to the Koyeb Documentation and Nari Labs.

