Ollama and Friends' Local and Open Source AI Developer Meetup at KubeCon Paris
After an amazing week of conferences, panels, and catching up with friends from all over the world, KubeCon and CloudNativeCon Europe 2024 has come to a close! Today, we would like to provide a recap for the meetup we threw during KubeCon Europe.
Last Thursday night, we co-organized a Local and Open Source AI developer meetup with Ollama and Dagger at Station F. Over 450 developers attended, both from the local and international scene. With KubeCon in town, it was a great opportunity to bring together the AI community.

The event gathered a remarkable collection of builders and included lightning talks from Timothée Lacroix (co-founder of MistralAI), Solomon Hykes (co-founder of Docker and Dagger), Paige Bailey (Lead Product Manger for DeepMind and Geneative AI at Google), Ollama, Koyeb, and more.
Did you miss out on the action or just want a recap of the evening’s presentations? The talks were recorded, so you can watch them below. We also wrote a quick recap that you can read below!
- MistralAI - Timothée Lacroix, Co-founder
- Google DeepMind and Generative AI - Paige Bailey, Lead Product Manager
- Ollama - Patrick Devine, Maintainer
- Dagger - Solomon Hykes, Co-founder and Creator of Docker
- Docker - Eli Aleyner, creator of Testcontainers
- LlamaIndex - Pierre Doulcet, AI Engineer
- Koyeb - Yann Léger, Co-founder
- dltHub - Akela Drissner-Schmid, Head of Solutions Engineering
- HelixML - Luke Marsden, CEO
- Neo4j - William Tai, Senior ML Engineer
Timothée Lacroix - Co-founder and CTO of MistralAI
Function Calling with Mistral’s Latest MOE Model
According to Tim, function calling is greatly underused with LLMs. For his demo, Tim decided to showcase how developers can leverage function calling to mix and match technology to address different use cases.
In honor of the week's KubeCon, Tim wanted to demonstrate how you can use function calling to interact with a Kubernetes cluster using natural language. The resulting interaction with the cluster would happen fully locally: this is an added precaution as Mistral cares about data and privacy.
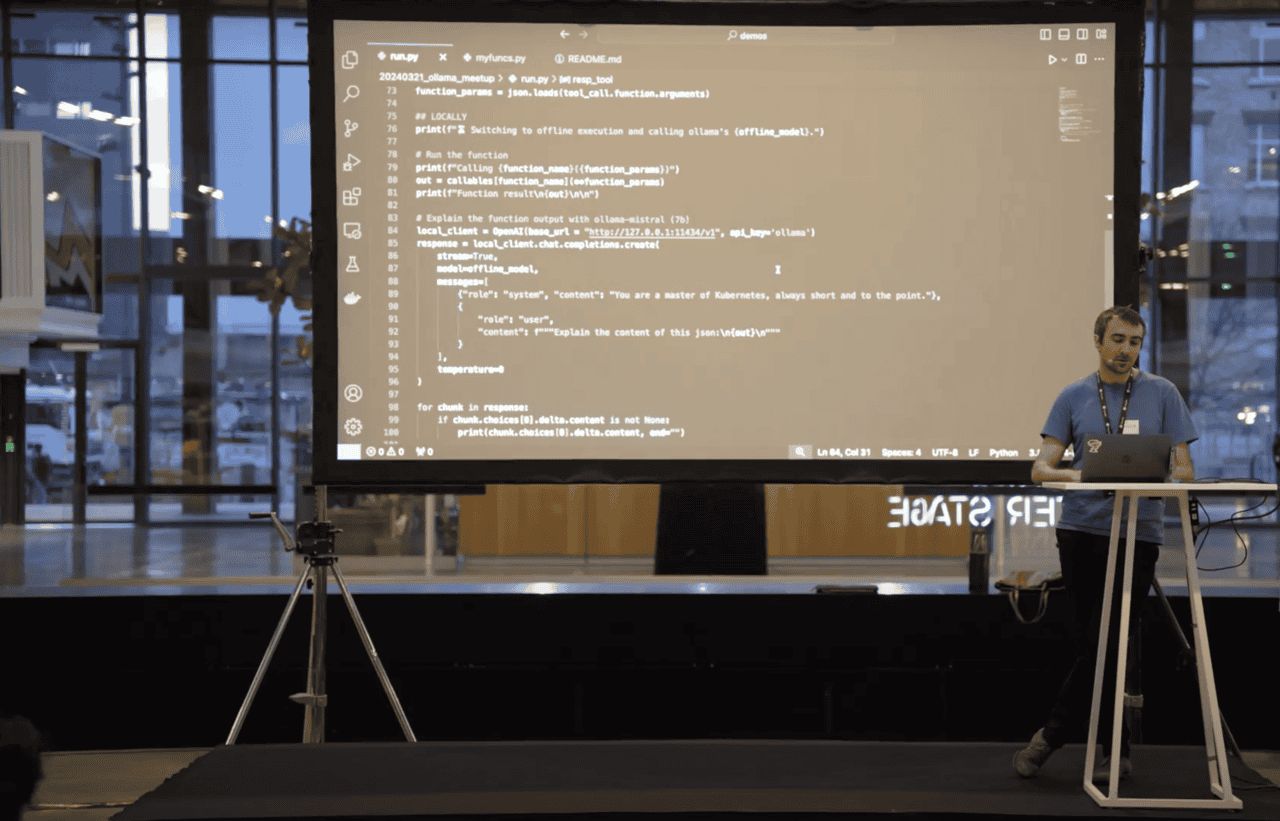
Tim ran two different models during the demo: Mistral-small (API) and Mistral-7B (locally on Ollama). He enabled function calling to interact with two different Kubernetes tools: one to list pods and the other to describe pods. In practice, Mistral-small would process Tim's question and assess which tool to use to interact with the cluster, then the tool execution and the output formatting by Mistral-7B would take place locally.
To showcase the final result, Tim showed Mistral local asking, "How can I help you?”, to which he asked, “Please explain this pod.” The response: It’s an NGINX pod.
Behind the scenes, Mistral's online model figured out which function to call. The function to describe the pod was then executed locally and leverages the local model to list and describe the pods.
Deploy your workloads on best-in-class infrastructure worldwide.
Paige Bailey - Lead Product Manager for Generative AI at Google
Gemma: Alphabet's Lightweight State-of-the-Art Models
Paige's demo showed you don't need big models to have long context, you can also make long context out of small models.
To start, Paige introduced Alphabet's Gemma, a family of light-weight, state-of-the-art open source models built from the same research and technology used to create the Gemini models. There are different Gemma versions, such as Gemma 2B and Gemma 7B parameter models, which are both instruction-tuned.
For the demo, Paige showed how you can use Gemma to increase developer productivity with AI and the magic of long context. The Gemini Pro 1.5 model can take in over 1M tokens in context length, meaning you can ingest a lot of the emails, text messages, calendars, code bases you use in your day-to-day.
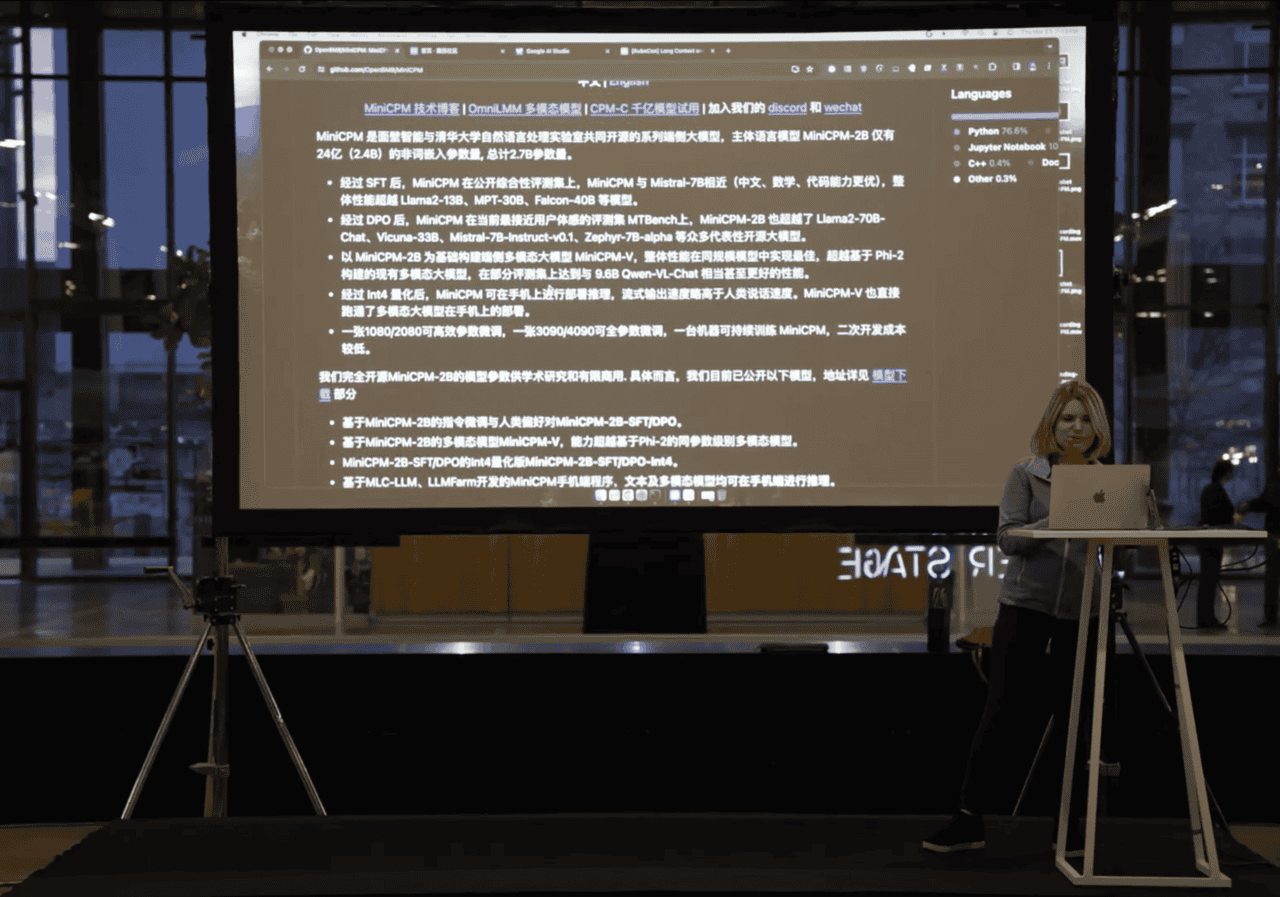
She uploaded the Ollama code base into Gemini 1.5 AI Studio and asked, "Hi Gemini! I'd like to add a new model to use in Ollama, called MiniCPM. The README for MiniCPM and the source code for Ollama are attached. Could you please implement that change for me, based on all the information I've shared?"
Please note, the README file is in Chinese. Not only did Gemini explained she would need to convert the model, but also it recommended the best link for the model on Hugging Face and explained how to convert, test, and run the model.
Patrick Devine - Maintainer for Ollama
Simplifying Model Importation into Ollama
Patrick's demo tackled the current obstacles users face when importing new models into Ollama and showcased the team's solution to simplify the process.
Importing models to Ollama is possible today and the entire process is outlined in their documentation. In short, after selecting a model, cloning it, and downloading everything, you need to convert the model into gguf format. This is because Ollama uses llamaccp on the backend, which requires the gguf format to run. To convert the model into this format, you need to run a convert script.
Once converted, you need to quantize the model. When you pull a model, you get it in PyTorch or in Safetensors format comes as 16bit value inside the model. Quantization is cutting that value down to 4 bits.
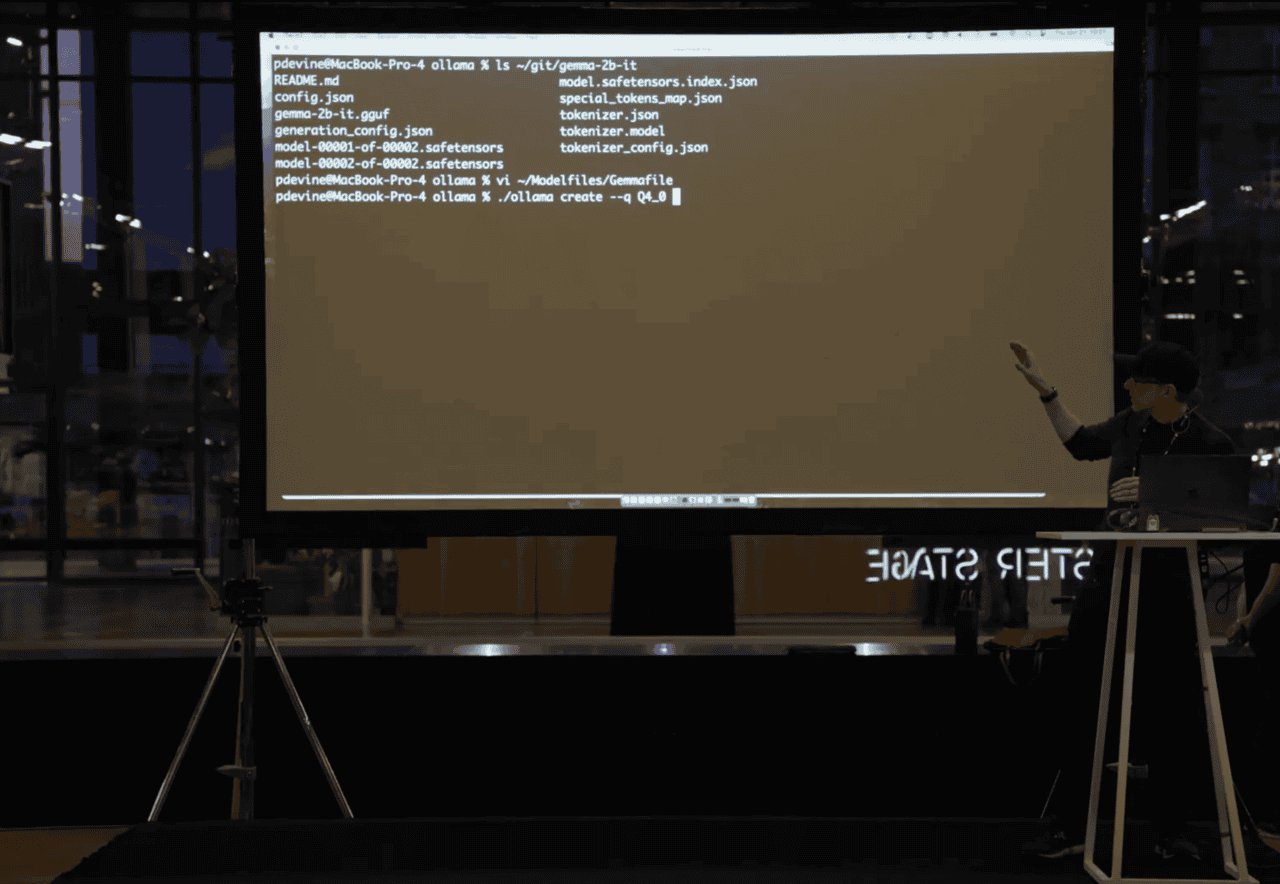
Next up, you need to create a model file. A model file is the blueprint to create and share models with Ollama. Patterned after Dockeriles, model files let you specify the model's quantized binary. You can put other things in your model files, like a chat template.
For the demo, Patrick went to Hugging Face and pulled the Gemma 2B model. After showing the different Safetensors format on his laptop that need to be converted, he demonstrated using the model file that has been created for Gemma. The model file has the same path to the model, specifies the chat template to be used, and other parameters. Once everything was running, he showcased the model in action!
Bonus demo at the end: Patrick showed us how quantization works!
Solomon Hykes - Co-founder Dagger and Creator of Docker
Leveraging Function Calls and AI to Dynamically Build Test Pipelines with Dagger
Solomon's talk brought together DevOps and AI, showcasing how the Dagger function primitive is an ideal solution for function calls in the AI world. A fun nod to Timothée's talk just before.
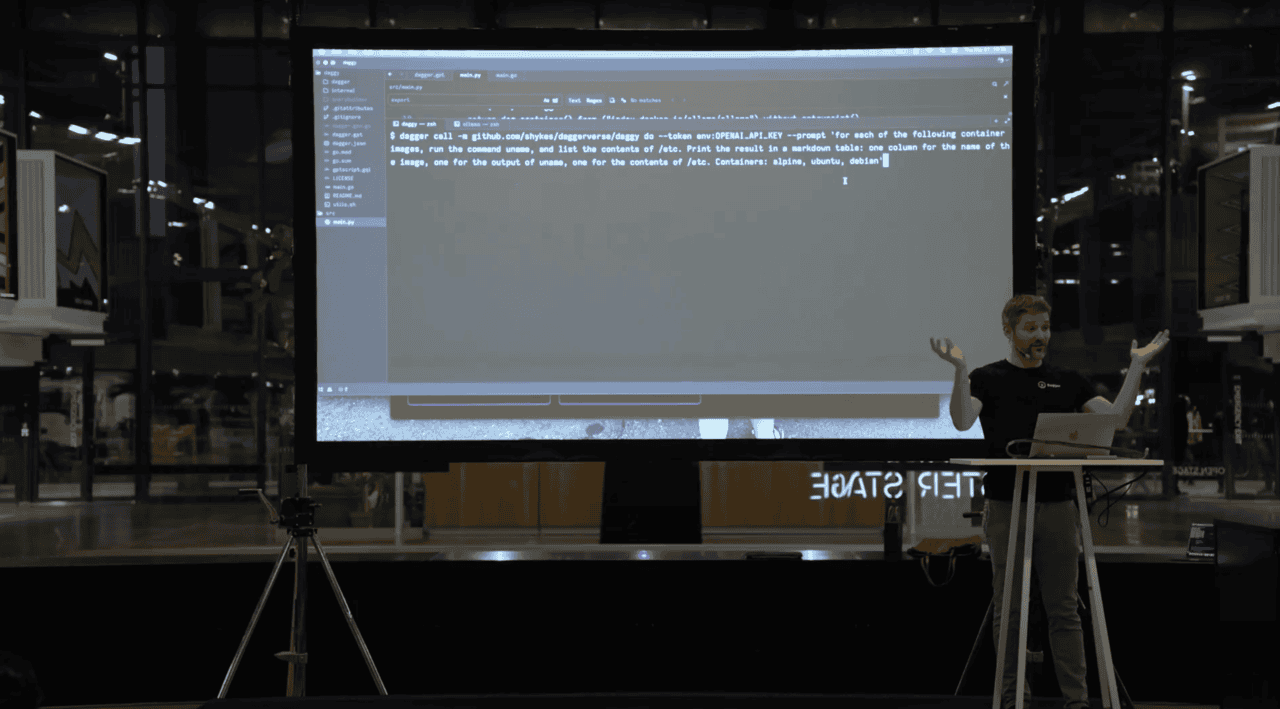
He kicked the demo off by explaining Dagger, a CI product to run pipeline and containers with modular functions. He pointed out how it is being used for AI workloads like GPTScript, a scripting framework for leveraging function calls built by Darren and Sheng.
The idea behind the demo is to show how an AI model will be able to automatically assemble the perfect pipeline using Dagger functions. He said imagine being able to say, “For these 10 repositories, pull all the tags. For each of these base images, run the Dockerfile, run the tests, show me all the results and give me nice red and green emojis”. Boom, an awesome test pipeline that AI is running for you.
After the demo, he reminded the audience, this is is not code generation. This is dynamically composing the pipeline for you.
Eli Aleyner - Docker and TestContainers
Streamlining Integration Testing with Test Containers
Eli's demo focused on testing. He introduced Test Containers, a Docker acquired project that simplifies integration testing for developers, and showcased its integration with local models. Test Containers is available in 9 languages, and more are coming! Over 100 integrations are available, including a large number of vector databases. More and more developers are building their first AI experience using models like LLaMA.
During his demo, Eli spun up Ollama with the Mistral model, made sure the model is running, and asked it a simple question, "What is Test Containers?" After showing that this worked, he then demonstrated iterating on the application in real-time and changed the model in use.
It worked! The test passed quickly because of what was happening under the hood: Test Containers was issuing requests through the network to Test Containers Cloud, an Edge Cloud Service with GPU support in preview.
Pierre-Loic Doulcet - LlamaIndex
Local RAG with LlamaIndex, Hugging Face, Ollama, and Mistral AI
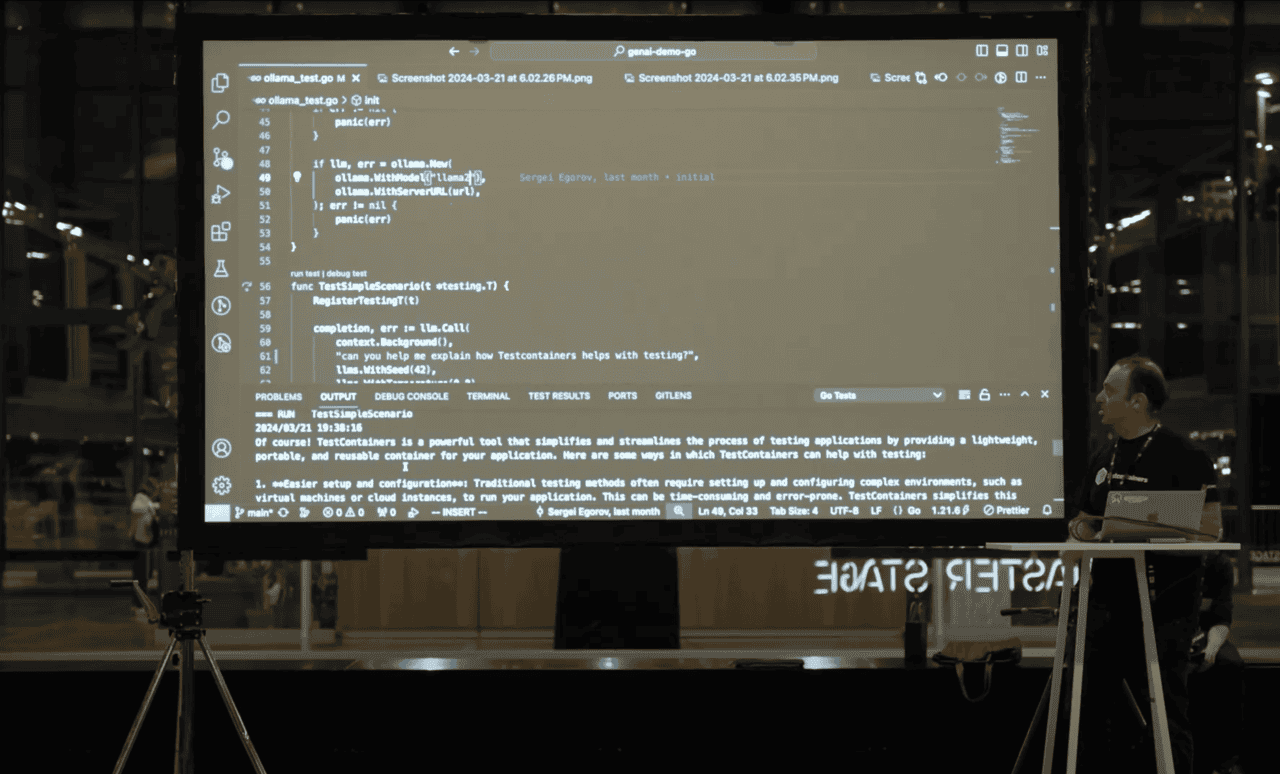
Pierre kicked off his talk asking who in the audience is familiar with RAG. He explained how RAG improves an LLM responses. Especially since LLMs do not know the specifities of your company.
In his demo, he showed how to perform RAG locally on your machine, using LlamaIndex as the orchestration framework, Hugging Face for the embeddings, and Mistral Ollama for the LLM.
After setting up his local environment with LlamaIndex and Hugging Face, he turned off his connection to the Internet. After all, this is a demo about performing RAG locally! He showcased how to create the index and query engine locally before using it to answer questions based on the index.
Yann Léger - Co-founder Koyeb
Global LLMs: Deploy Ollama and AI workloads worldwide in 5 minutes
Yann's demo showed how to deploy a serverless Ollama inference endpoint across 3 continents. He kicked off his demo by introducing the Koyeb platform.
Leveraging Koyeb's one-click Ollama app, Yann showed how easy it was to select the regions where developers can deploy their applications and how fast it is to deploy Ollama worldwide.
Once the model was up and running, Yann asked it a simple question, "Why is the sky blue?"
Behind the scenes, end users requests are routed to the closest running instance thanks to the platform's built-in edge network and support for multi-region deployment. In practice this means:
- Requests from users in the US are routed to Washington, D.C.
- Everyone at KubeCon's requests are routed to the Paris
- Users in South East Asia are routed to Singapore
While this demo ran on high-performance CPUs, Koyeb will soon be offering the same deployment experience with serverless GPUs and high-performance accelerators.

Akela Drissner-Schmid - dltHub and continue.dev
Fine-Tuning Open Source LLMs for Better Code Prediction
Akela demoed how to improve autocomplete suggeestions for code completion by fine-tuning an open source LLM. She introduced dlt, a Python library that automates data loading with features like schema creation, normalization, and integration adaptability.
During her demo, she introduced Continue.dev, an open-source Github co-pilot that works with any open source model available with Ollama.
She experimented with starcoder2, selecting the smallest version with 3B parameters, and trained it on all dlt's code and GitHub repositories. This took about 30-60 minutes. Once it was fine-tuned, she shared it with her engineering team using the process Patrick discussed earlier. She is excited to hear the process is getting easier!
Comparing autocomplete suggestions from a non-fine-tuned model to the fine-tuned one, Akela demonstrated the fine-tuned model provided more accurate predicitons. She noted some occasionally weird notation and mentioned this is something they want to work on.
Going further, she asked the question, "How useful is it to fine-tune a model on their own code bases versus data from the continue.dev tool?" Since Continue dumps the usage data in a JSONL file, dlt decided to leverage that data to futher fine-tune the model.

Luke Marsden - HelixML
Integrating APIs with Local LLMs with Helix Tools
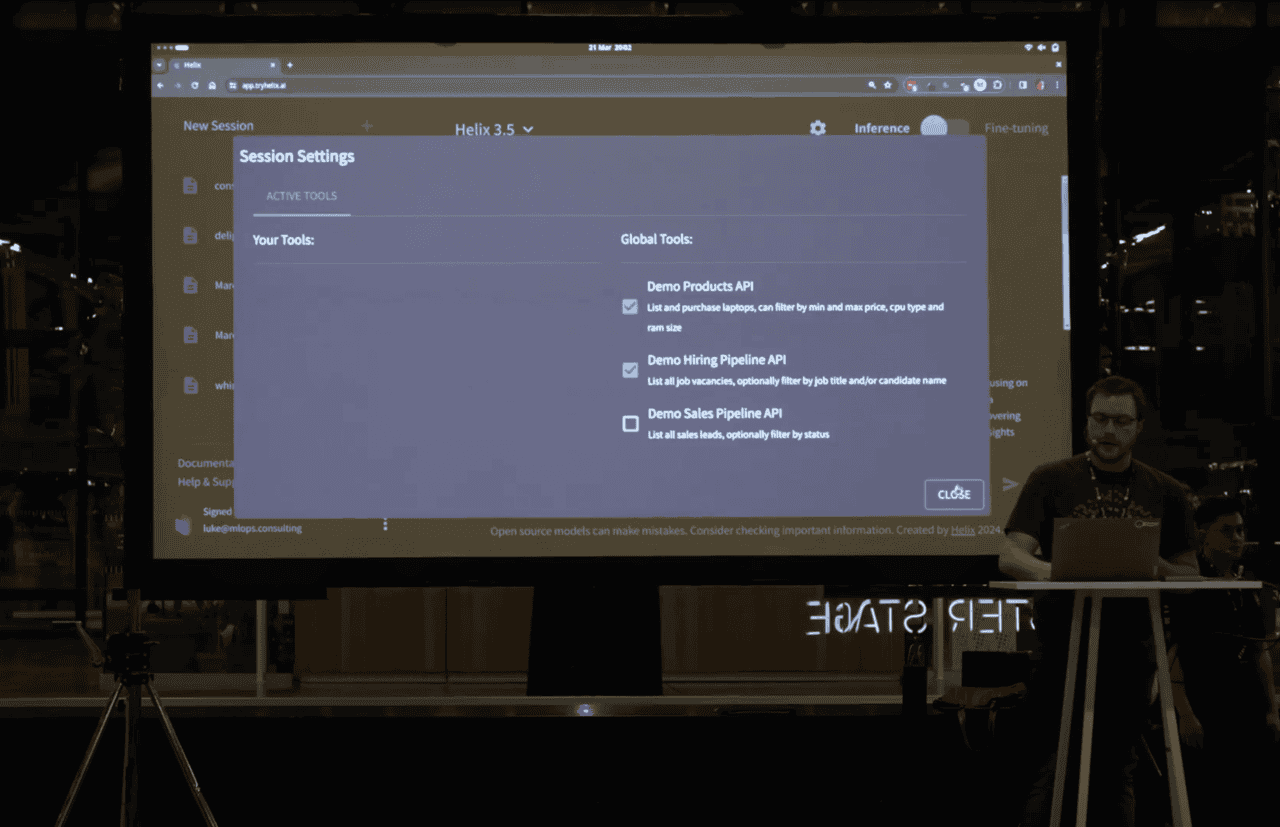
During the demo by HelixML, Luke announced Helix Tools. Helix Tools enable you to call any API from a local open source LLM running in Ollama. The release also added the ability to plug in APIs to your chat session.
To showcase this, he started with Helix and where you can integrate APIs. It's interesting when you have local private LLMs that you want to integrate with your business systems containing private data.
His demo had a Hiring Pipeline API and Products API. In his Hiring Pipeline API, he has data about candidates and open positions. The Products API contains data about company equipment. The demo showed how these APIs can interact together to provide a better response for questions regarding hiring and the equipment they need to do their jobs.
In the second part of his demo, Luke automated programatically interfacing with the Tools API using Dagger. He did a simple call for the Dagger module for Helix, making it very easy to test and run Helix.
Luke's demo showcased how users can integrate an LLM running on Ollama with corporate APIs, then run it from Dagger. He wrapped things up by quickly diving into Helix's architecture.
See the slides from Luke's demo.
William Tai - Neo4j
Constructing Knowledge Graphs from Unstructured Data
Will kicked off his demo asking who in the audience is familiar with Neo4j and knowledge graphs?
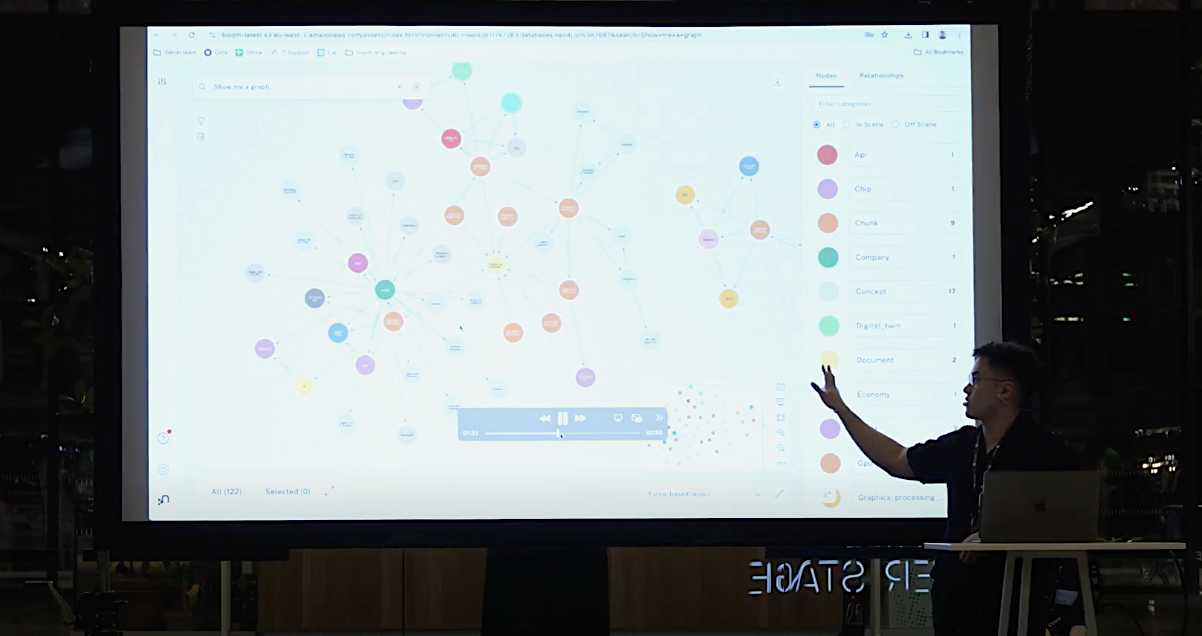
A knowledge graph captures information about entities in your domain and the relationships in between them. In practice, that means that you define your nodes in your graph to represent your data. You can have properties associated with those nodes. Once you've set up your knowledge graph, you can use it to ask questions.
In his demo, Will imported unstructured data into his database: a YouTube video about NVIDIA GTC 2024 highlights and a Wikipedia link for Blackwell (microarchitecture). He then started using the visualization tool to visualize his data and knowledge graph.
To wrap the demo up, Will showed off some of Neo4j's impressive built-in features like being able to chat with your data.
Paris’ Open Source AI Scene is on Fire
We had an amazing time getting the AI community together! We are thankful to everyone who attended and to all our awesome speakers for getting on stage to perform a quick demo.
This was our first local and open source AI developer event in Paris, and it surely will not be our last. Follow us on X @gokoyeb and join our Slack community to stay in the loop about our next events. We had a blast helping Ollama and Dagger organize this amazing meetup for the AI developers in Paris.
If you want to deploy AI workloads on high-performance GPUs and next-generation accelerators, join our technical preview.