What is RAG? Retrieval-Augmented Generation for AI
Retrieval-augmented generation (RAG) is an AI framework and powerful approach in NLP (Natural Language Processing) where generative AI models are enhanced with external knowledge sources and retrieval-based mechanisms. These appended pieces of outside knowledge provide the model with accurate, up-to-date information that supplements the LLM’s existing internal representation of information.
As the name suggests, RAG models have a retrieval component and a generation component.
- The retrieval component fetches relevant information from an external knowledge base, for example, information stored as vector embeddings in a vector database.
- The generation component is responsible for creating a response based on the retrieved information.
Thanks to these two processes, RAG models improve the quality of LLM-generated (large language model) responses by providing more accurate, contextually relevant, and informative responses.
In this primer, we are going to talk about the origin of RAG, how RAG works, the benefits of using RAG for your LLM applications, and share some ideal use cases. We'll also show you how to implement it for your models and deploy RAG-powered AI applications.
Origins of RAG: the quest to build a more perfect question-answering system
To start, it might help to take a step back and look at the larger field RAG exists in. RAG is just one of the latest improvements for question-answering systems, also known as systems that automatically answer natural language questions.
The history of building question-answering systems dates back to the 1960s and the early days of computing. There was SHRDLU that could interact with users about a small and pre-defined world of objects. Then, there was Baseball, a program that answered natural language questions about stored data it had on baseball games. These are just two early examples of retrieval systems, where the problem was primarily about locating relevant documents or data and returning them.
Fast forward to the '90s, and you might remember when a new sensation popped up on the nascent Internet: Ask Jeeves. Essentially, Ask Jeeves was a question-answering system that was in the business of providing a similar experience of the likes to today's Amazon's Alexa, and AI-powered search like Bard and Bing. A full circle moment, that is not lost on the creator of Ask Jeeves.
Ask Jeeves preceded Google, but as you might know, it did not win the Internet search battle. While both aimed to answer natural language questions with the most relevant information on the Internet, search engines like Google pulled ahead for a few reasons. One of them is Google's algorithm and technology for indexing and ranking web pages. This ability to index and identify the most relevant information is still just as important today as it was at the start of the 2000s.
Moving into the 2010s, IBM's Watson took the world by storm when it outwhizzed Jeopardy heavyweights Ken Jennings and Brad Rutter. Watson was a question-answering system that was trained on over 200 million documents. It could understand natural language and answer questions with a high degree of accuracy. With Watson, IBM demonstrated technology's ability to rapidly answer natural language questions with factually correct information. It was an advancement in question-answering systems that laid the groundwork for the next generation of generative models.
As the decade continued, more advanced neural models for natural language processing continued to evolve, and solutions to previous limitations of retrieval systems started to emerge.
Fun fact about the name, RAG
The term RAG was coined by Patrick Lewis and his research team in the paper Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Lewis has joked that had he and his research team known the acronym would become so widespread, they would have put more thought into the name.
How does RAG work?
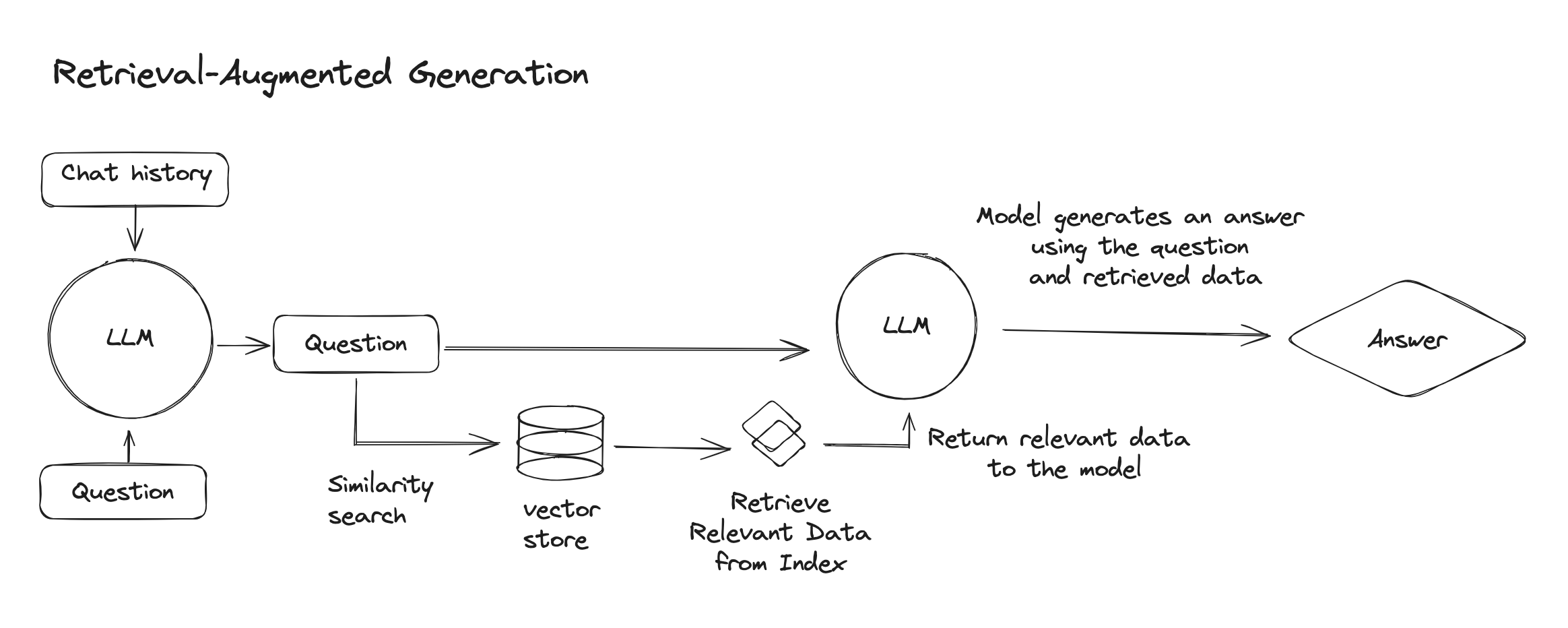
RAG has some core building blocks: a pre-trained LLM (responsible for generating text, images, audio and video), vector search (retrieval system responsible for finding relevant information), vector embeddings (aka vectors aka embeddings, essentially numerical representations of semantic or underlying meaning in natural language of data), and generation (combines the output of the LLM with information from the retrieval system to generate the final output)
Here is a very high-level understanding of how RAG works: when an LLM initiates a query, it prompts an AI model to transform the query into a numerical representation, also known as a vector embedding, that is machine-readable. This embedding model then compares these vectors within a machine-readable index of a pre-existing knowledge base, such as a vector database.
When the embedding model finds a match, it retrieves the corresponding data, converts it to human-readable text and returns it to the LLM. Finally, the LLM combines the retrieved data with its own generated response to the initial query, creating and returning a final answer.
Benefits of using RAG: Accuracy, trust, time and cost optimization, and customization
Adding RAG to an LLM-based question-answering system has four key benefits:
- Accurate and up-to-date information: Using RAG gives the model access to the most current and reliable facts.
- Builds trust: RAG helps provide those using the model access to the model’s sources, helpful when you need to verify claims for accuracy and trustworthiness. Additionally, RAG helps the model to recognize and admit when it does not know the answer to a question, rather than just hallucinating.
- Time optimization: RAG reduces the need to continuously train models on new data and update its parameters as circumstances evolve. Not just a time saver, RAG can lower the financial costs of running LLM-powered applications.
- Customization: Leveraging RAG is an efficient way to personalize responses on LLMs, allowing you to tailor the model to your specific needs by adding knowledge sources.
Who is using RAG?
RAG is a major improvement to modern question-answering systems. Any role or industry that relies on answering questions, performing research and analysis, and sharing information will benefit from models that leverage RAG. Here are just a few example scenarios:
- Conversational Chatbots for Enhanced Customer Service: Accessing the latest information from a company's knowledge base can help chatbots provide more accurate and up-to-date answers to customer queries.
- Personalized recommendation systems: By leveraging RAG, recommendation systems can offer tailored and up-to-date suggestions to users based on their preferences, behaviors, and contextual information, enhancing user engagement and satisfaction.
- Legal research and workloads: Legal professionals, including lawyers and legal assistants, gain access to up-to-date case laws and regulations, streamlining research processes and boosting legal work efficiency.
- Financial analysts: Analyzing vast amounts of real-time market data becomes significantly more efficient when using models that leverage RAG.
Again, these are just a few general examples of how RAG can be used. Since almost every industry and role requires access to accurate and up-to-date information, there are plenty of opportunities where RAG can be leveraged.
How to implement RAG in your LLM and AI applications?
The RAG-Token model from the paper Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks is just 5 lines of code. If you want to follow a step-by-step tutorial, we have a guide showcasing how to build a RAG-powered chatbot.
Conclusion
RAG is just one of the growing family of methods for expanding an LLM's world knowledge and decision-making ability. It takes an open-book approach to answering questions that were previously difficult for LLMs.
While some speculated long context windows could render RAG obsolete, others like David Myriel point out these require more computational resources and longer processing times.
In the meantime, RAG is a powerful tool for improving the quality of LLM-generated responses. If you are looking for a way to deploy a RAG-powered AI application, Koyeb is your new go-to deployment platform.
The platform runs on high-performance bare metal servers and provides a powerhouse collection of built-in features to run your AI workloads globally. Focus on building and improving your AI applications without worrying about infrastructure management.