How to Deploy a REST API with Flask, Fauna, and Authentication on Koyeb
Introduction
In this tutorial, we will build a REST API using Flask and a Fauna database. The API will provide authentication capabilities to let users sign up, log in, log out, and access their account information when logged in.
Flask is a lightweight web framework written in Python that offers developers a range of tools and features to create web applications with flexibility and ease. Fauna is a transactional serverless database available as a cloud API with native GraphQL that provides a simple, secure, and reliable way to store and query data.
We will deploy our application to Koyeb using git-driven deployment, which means all changes we make to our application's repository will automatically trigger a new build and deployment on the serverless platform. By deploying on Koyeb, our application will benefit from native global load balancing, autoscaling, autohealing, and auto HTTPS (SSL) encryption with zero configuration on our part.
Requirements
To follow this guide, you will need:
- A local development environment with Python installed
- A GitHub account to version and deploy your application code on Koyeb
- A Fauna account to run the database our application will use
- A Koyeb account to deploy and run the Flask REST API
Steps
To build a REST API with Flask and Fauna, implement authentication, and deploy it on Koyeb, you will need to follow these steps:
- Initialize a Flask application
- Set Up RESTX
- Configure the Fauna Database
- Add Authentication to the Flask App
- Add Seed Data and Role-Based Authorization
- Error Handling
- Deploy the Flask Fauna REST API on Koyeb
- Conclusion
Initialize a Flask application
Get started by creating a new project folder in your terminal. Then create a virtual environment and install the required dependencies for the project in that folder. Do this by running the following in your terminal:
mkdir flask-fauna
cd flask-fauna
python3 -m venv venv
source venv/bin/activate
pip install flask faunadb flask_restx python-dotenv
A virtual environment is a folder that contains a copy of your Python interpreter. We use this to isolate our packages from the rest of the system. This way, when Flask or any other dependencies are installed, they will only be used for this project.
In this guide, to build our application, we will use the following modules:
Flaskis the web framework we are working with.faunadbis the library for interfacing with Fauna.flask_restxwill be used to create a Flask REST API.python-dotenvwill let us load environment variables from a.envfile, for authorizing interactions with Fauna.
Create a file/folder structure for our project:
touch .env app.py api.py seed.py gunicorn_config.py
mkdir auth
touch auth/controller.py auth/parsers.py auth/repository.py auth/serializers.py
The result should look like this:
flask-fauna
├── .env
├── app.py
├── api.py
├── seed.py
├── gunicorn_config.py
├── auth
│ ├── controller.py
│ ├── parsers.py
│ ├── repository.py
│ └── serializers.py
└── venv
A quick explanation about these files:
.envis a file that will contain environment variables for interacting with Fauna.app.pyis the main file for our application.api.pyis the file where we will initialize and configure our REST API.seed.pywill seed our database with some data.gunicorn_config.pyis a configuration for Gunicorn, which we will use for deployment at the end.authis the folder where we will write all the logic for authentication.
Initializing the Application
Now that we have set up our project structure, open the app.py file and add the following code:
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello_world():
return "<p>Hello, World!</p>"
This code creates a simple Flask app that returns the HTML <p>Hello, World!</p> from the / route.
To start up the Flask app and ensure everything is working as expected, run the following command:
flask run
If you visit 127.0.0.1:5000 in your browser, you will see the "Hello, World!" from the return statement.
Set Up RESTX
With our Flask app created, we will then use the Flask-RESTX library to help us build our REST API routes.
In api.py, add the following code:
from flask_restx import Api
authorizations = {
'apiKey': {
'type': 'apiKey',
'in': 'header',
'name': 'x-access-token'
}
}
api = Api(
version='1.0',
title='Flask/Fauna REST API',
description='A simple Flask/Fauna REST API',
authorizations=authorizations
)
Here we define the authorizations variable and initialize an API. The API's authorizations dictate that a user must provide an x-access-token header to perform certain requests that we will define later.
The original route we set up was intended to serve basic HTML. Now, we will replace it with a Blueprint for the /api route that is constructed from the api
object we created earlier in api.py. To integrate our Flask app with the REST API, we need to replace our original route in app.py with the following:
from flask import Flask, Blueprint
from api import api
app = Flask(__name__)
blueprint = Blueprint('api', __name__, url_prefix='/api')
api.init_app(blueprint)
app.register_blueprint(blueprint)
def main():
app.run(debug=False)
if __name__ == "__main__":
main()
At this point, if we run our Flask app and visit 127.0.0.1:5000/api in our browser, there will be nothing there. That is because we haven't defined any namespace yet. We will do that next.
Configure the Fauna Database
For the next part, we are going to create a Fauna database and retrieve the keys necessary to access this database in our project.
From the Fauna dashboard, create a database by clicking Create a database. Then, from the sidebar list for this database, click Security to create two new secret keys:
The first key should have the "Admin" role. The second should have the "Server" role:
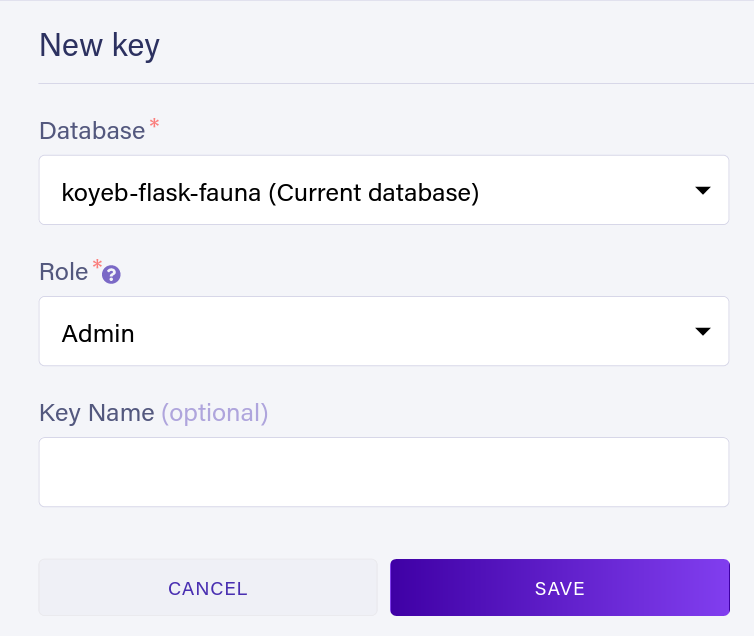
Store these keys in a file called .env in the root directory of your project like so:
FAUNA_ADMIN_SECRET=<admin-secret>
FAUNA_SERVER_SECRET=<server-secret>
Notice: Please do not commit this file to your repository. It is considered best practice to git ignore it. We will do this later in the Deploying to Koyeb section.
Add Authentication to the Flask App
Earlier, we created auth and populated it with the following files:
controller.py- This will contain the logic for our authentication API.parser.py- This will contain the logic for parsing request bodies (e.g. email and password).repository.py- This will contain the logic for interacting with Fauna.serializer.py- This will contain the logic for serializing the response.
These four files will be used to create the endpoints and logic for our API. Specifically, we will define the functionality for logging in, logging out, signing up and retrieving the user's account data.
Building the API
In controller.py, we will import our other previously created auth files, along with our api file, and then define a namespace. This namespace will be used to define the endpoints for our API. Route logic essentially parses the request and passes it to the appropriate function in repository.py.
Go to controller.py and add the following:
# Import flask's `request` and flask_restx's `Resource` objects.
from flask import request
from flask_restx import Resource
# import other `auth` files
from auth import parsers
from auth import repository
from auth import serializers
from api import api
# define a new namespace called `auth` and set its description.
ns = api.namespace('auth', description='Operations related to authorization')
# create class and end point for user log in
@ns.route('/login')
class Login(Resource):
# `@api.expect` is used to define the request body that we expect to receive.
@api.expect(parsers.login_args)
# `@api.marshal_with` is used to define the response body that we will send back.
@api.marshal_with(serializers.token)
def post(self):
"""
Exchange credentials to access token
"""
# uses a parser we will define soon called `login_args` to parse the request body and give us the `email` and `password` fields.
credentials = parsers.login_args.parse_args(request)
# takes the `email` and `password` field data to `repository`'s login function, which we will define later.
response = repository.login(
credentials.get('email'), credentials.get('password'))
# return a response object which contains the `x-access-token` which is used later to authenticate certain requests
return {"access_token": response.get("secret")}
# create class and end point for user log out
@ns.route('/logout')
class Logout(Resource):
# Notice that `@api.doc(security='apiKey')` is used to add a security requirement to this endpoint.
# This is because we need the `x-access-token` to log out the user.
@api.doc(security='apiKey')
def post(self):
"""
Logout user
"""
# Logout takes in that `x-access-token` and calls the `logout` function in `repository.py` to log out the user.
repository.logout(request.headers.get("x-access-token"))
return {'message': 'Logout successful'}
# create class and end point for user sign up
@ns.route('/signup')
class Signup(Resource):
@api.expect(parsers.login_args)
@api.marshal_with(serializers.token)
def post(self):
"""
Create user and exchange credentials to access token
"""
credentials = parsers.login_args.parse_args(request)
repository.signup(credentials.get('email'),
credentials.get('password'))
response = repository.login(
credentials.get('email'), credentials.get('password'))
# return a response object which contains the `x-access-token` which is used later to authenticate certain requests
return {"access_token": response.get("secret")}
There is a lot going on in that snippet. In short, we defined a new class for each route in the namespace: login, logout, signup, and users. We also defined a new endpoint for each of these routes.
Now that we have our auth namespace, we can add it to our api variable in app.py:
# Import the namespace we just created
from auth.controller import ns as auth_namespace
app = Flask(__name__)
blueprint = Blueprint('api', __name__, url_prefix='/api')
api.init_app(blueprint)
# Add the auth namespace to the API
api.add_namespace(auth_namespace)
flask_app.register_blueprint(blueprint)
A blueprint is a way to organize a Flask app's routes. We will use it to define and group routes together, so they are easier to manage. In this case, we grouped our auth routes in that auth namespace and added them to the blueprint for /api so Flask can work with them.
Now that our API has a namespace to work with, /api will respond with Swagger, which is a part of Flask-RESTX for documenting and testing APIs:
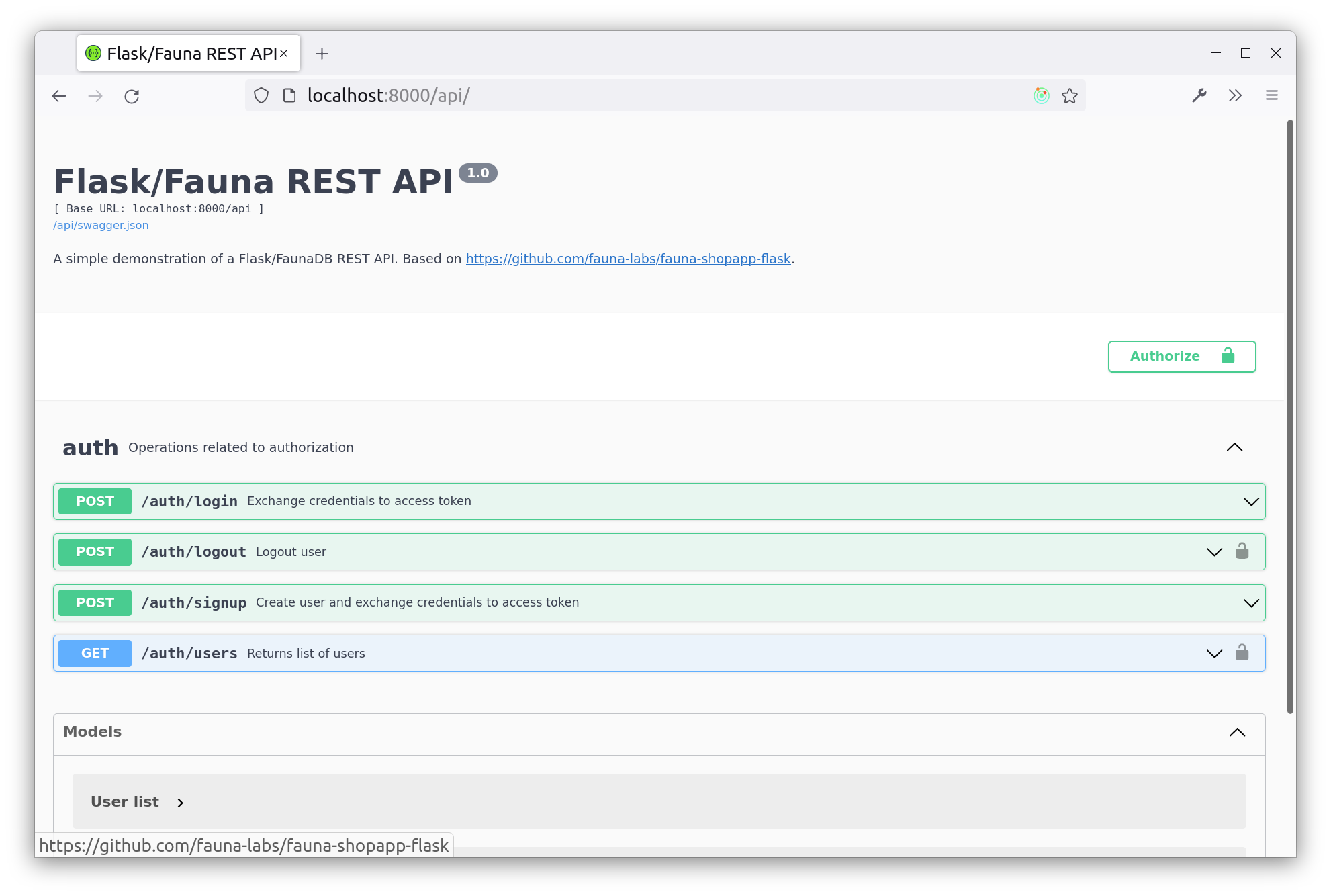
This UI will provide forms for us to test out endpoints based on the @api.expect decorator.
Now, we will go to parser.py and add the following code, so we can parse the request body:
from flask_restx import reqparse
login_args = reqparse.RequestParser()
login_args.add_argument('email', location="form", required=True)
login_args.add_argument('password', location="form", required=True)
In this file, we created a new request parser and defined the two fields: email and password that it requires.
Next go to serializers.py and add the following:
from flask_restx import fields
from api import api
token = api.model('Tokens', {
'access_token': fields.String(readOnly=True, description='Access token')
})
This file indicates what will be returned in the response body of a request. So, as an example, if an endpoint has the @api.marshal_with(serializers.token) decorator, it will return an object with the access_token field.
Query Logic
Next we're going to start interacting with Fauna, so we can perform queries.
We will use python-dotenv to read the .env file, so we can use the secrets to make requests to Fauna.
Then, we will set up the Fauna query logic in the repository.py file. In this case, we will be using the FAUNA_SERVER_SECRET environment variable to perform server operations. User requests will use their access token as a secret for their own Fauna operations.
Go to repository.py and add the following:
import os
from dotenv import load_dotenv
from faunadb import query as q
from faunadb.client import FaunaClient
load_dotenv()
FAUNA_SERVER_SECRET = os.getenv("FAUNA_SERVER_SECRET")
fauna = FaunaClient(secret=FAUNA_SERVER_SECRET)
def login(email, password):
# Because `q.login` is a part of the Fauna query language, Fauna will do the work of returning a
# temporary access token for the user.
return fauna.query(
q.login(q.match(q.index('user_by_email'), email),
{"password": password}))
def logout(secret, status=False):
client = FaunaClient(secret=secret)
return client.query(
q.logout(status))
def signup(email, password):
# Here, the `q.create` function takes in a collection and an object that will be added to the collection.
return fauna.query(
q.create(
q.collection("users"),
{
"credentials": {"password": password},
"data": {
"email": email,
"type": "user"
},
}
)
)
Here is a summary of what is happening in the snippet above:
- We got the
FAUNA_SERVER_SECRETfrom the environment variables. - We create a new FaunaClient object with that secret. This FaunaClient client will be able to perform server operations such as creating new users.
- User-specific operations will use their access token as a secret (e.g. logout and get_users).
- We query Fauna for a user with the given
emailandpassword.
Note: We haven't defined the users collection yet. We will do that a little later in the Creating a Seed file section.
Add Account Data Retrieval Support
The final endpoint we will add to our API is to retrieve the user's account data. In controller.py add the following route:
@ns.route('/users')
class Products(Resource):
@api.doc(security='apiKey')
def get(self):
"""
Returns list of users.
"""
return repository.get_users(request.headers.get("x-access-token"))
You will notice that this function returns a list of users. When we create the seed file later, we will indicate roles for each user. Admin users will get a complete list of users, while regular users will only get a list containing their own user data. For now, this endpoint will return a list of all users.
Next, write the logic for retrieving user data from Fauna in repository.py:
def get_users(secret):
client = FaunaClient(secret=secret)
# An index is a way to query Fauna for a specific field. We will create this later in seed.py.
data = client.query(q.map_(
lambda ref: q.get(ref),
q.paginate(q.documents(q.collection('users')))
))['data']
return list(map(lambda user: user['data'], data))
This function does two things:
- It creates a FaunaClient with the given
secretand then queries Fauna for all users. - It maps over the list of users and returns a list of data (email and role type) for each user.
Add Seed Data and Role-Based Authorization
Now that our Flask app can talk to Fauna, we are going to populate our database with some seed data that we can work with.
In your project folder, create a seed.py file. This file will be responsible for creating the users collection, populating it with some example users, and
the user_by_email index we used earlier.
In seed.py add the following:
from faunadb import query as q
# create `users` collection
def create_collection(client):
client.query(q.create_collection({"name": "users"}))
# create index for users' emails
def create_indexes(client):
index = {
"name": "user_by_email",
"source": q.collection("users"),
"terms": [{"field": ["data", "email"]}],
}
client.query(q.create_index(index))
The index source is the collection it will be used on. The terms field is the field we will use to index the data. In this case,
we are indexing the email field in data.
Now for the fun part, seeding users. In seed.py add:
def seed_users(client):
client.query(q.map_(
lambda userRef: q.delete(userRef),
q.paginate(q.documents(q.collection('users')))
))
users = [
{"data": {"email": "foo@koyeb.com", "type": "admin"},
"credentials": {"password": "verysecure"}},
{"data": {"email": "bar@koyeb.com", "type": "user"},
"credentials": {"password": "thebestpasswordever"}},
{"data": {"email": "foobar@koyeb.com", "type": "user"},
"credentials": {"password": "theanswertoallquestions"}},
]
client.query(q.map_(
lambda user: q.create(q.collection('users'), user),
users
))
This function performs two actions:
- Delete all users in the
userscollection, in case you've already run the script before. - Create new users by running the
usersarray throughq.map_and executing the lambda function to create each user in theuserscollection.
Notice that we defined types for each user. This is so we can control access to user data in the next step.
But before that, we are going to call these functions as a Fauna admin in seed.py:
import os
from dotenv import load_dotenv
from faunadb.client import FaunaClient
load_dotenv()
FAUNA_ADMIN_SECRET = os.getenv("FAUNA_ADMIN_SECRET")
fauna = FaunaClient(secret=FAUNA_ADMIN_SECRET)
# ...
create_collection(fauna)
create_indexes(fauna)
seed_users(fauna)
To execute our seed.py file, we will need to run the following command:
python3 -m seed.py
A FaunaClient with the admin secret is the only way to create certain types of data in Fauna. A great example being roles, which we will be adding next.
Restricting Data With Roles and Attribute-Based Access Control
Now comes the interesting part. We will create some roles for our app's users and use these roles to restrict access to certain user data.
In our seed.py file, define an admin role and a user role:
def create_roles(client):
roles = [
{
"name": "admin",
"membership": [
{
"resource": q.collection("users"),
"predicate": q.query(lambda ref: q.equals(q.select(["data", "type"], q.get(ref)), "admin"))
}
],
"privileges":[
{
"resource": q.collection("users"),
"actions": {
"read": True,
"create": True,
"write": True
}
}
]
},
{
"name": "user",
"membership": [
{
"resource": q.collection("users"),
"predicate": q.query(lambda ref: q.equals(q.select(["data", "type"], q.get(ref)), "user"))
}
],
"privileges":[
{
"resource": q.collection("users"),
"actions": {
"read": q.query(lambda ref: q.equals(q.current_identity(), ref)),
"write": q.query(lambda ref: q.equals(q.current_identity(), ref)),
}
}
]
}
]
client.query(q.map_(
lambda role: q.create_role(role),
roles
))
create_roles(fauna)
Here, the membership field determines which users are assigned a specific role. In this case, we are assigning roles based on the
user's type. The privileges field determines what actions the role can perform on the data.
In this case, we are restricting the user role to only be able to read and write their own data, while the admin role can read
and write any data.
Now, when we query /users as a user, we will get only the current user's data. But if we query /users as an admin, we will get the
data for all users.
Error Handling
You may have noticed that if you try to sign out or get users without signing in first, you will get a 500 error. This is because
the logout query is performed without an x-access-token, so the FaunaClient created in repository.py will have a null secret.
Fauna handles this error internally, but we should never report these errors through the API. To fix that, go to app.py and add the
following error handling:
from faunadb import errors as faunaErrors
@api.errorhandler(faunaErrors.BadRequest)
def fauna_error_handler(e):
return {'message': e.errors[0].description}, 400
@api.errorhandler(faunaErrors.Unauthorized)
@api.errorhandler(faunaErrors.PermissionDenied)
def fauna_error_handler(e):
return {'message': "Access forbidden"}, 403
Internally, our Flask application is still producing the same errors (e.g. faunaErrors.Unauthorized when there is no
x-access-token), but now the API will understand and report that it is a bad request instead of a fault in the server's logic. Now, when we try to log out before logging in, we get a 403 Forbidden error.
Deploy the Flask Fauna REST API on Koyeb
It is time for the most exciting part! We are going to deploy our Flask app to Koyeb for the world to use.
Start by adding the following to gunicorn.conf.py:
bind = "0.0.0.0:8080"
workers = 2
Here we are instructing Gunicorn to run on port 8080, which is the default port for it to interface with Koyeb. We are also telling Gunicorn to use two workers, so at any time our API can handle two requests at once.
We are going to deploy our application on Koyeb using git-driven deployment with GitHub. But, before we do anything involving GitHub, create a .gitignore file in your project directory to avoid committing our .env file to GitHub.
Create a .gitignore file to your project folder and add the following to it:
# dotenv
.env
Next, create a new GitHub repository from the GitHub web interface or using the GitHub CLI with the following command:
gh repo create <YOUR_GITHUB_REPOSITORY> --private
Initialize a new git repository on your machine and add a new remote pointing to your GitHub repository:
git init
git remote add origin git@github.com:<YOUR_GITHUB_USERNAME>/<YOUR_GITHUB_REPOSITORY>.git
Add all the files in your project directory to the git repository and push them to GitHub:
git add .
git commit -m "Initial commit"
git push -u origin main
Once your code is on GitHub, go to the Koyeb Control Plane and on the Overview tab, click Create Web Service to begin:
- Select GitHub as the deployment method.
- In the repository list, select the repository containing your Flask Fauna REST API project.
- In the Builder section, click the Override toggle associated with the Run command and enter
gunicorn --worker-tmp-dir /dev/shm app:appin the field. - In the Instance section, choose Small or larger since we need at least 1 GB of RAM.
- In the Environment variables and files section, click Add variable and create two variables with the Secret type called
FAUNA_ADMIN_SECRETandFAUNA_SERVER_SECRET. Set the values of these Secrets to be the ones we stored in.envfile. - Choose a name for your App and Service and click Deploy.
That's it! Your app is now deployed to Koyeb. You will land on the deployment page, where you can follow the progress of your Flask Fauna REST API's deployment. Once the build and deployment are completed, you can access your application by clicking the App URL ending with koyeb.app in the Koyeb control panel.
If you want to learn about how Koyeb automatically builds your Flask and Fauna REST API from git, make sure to read our how we build from git documentation.
Conclusion
You now have a working REST API built with Flask and Fauna that is secured with roles and running on Koyeb. With Koyeb's git-driven deployment, a new build and deployment for this application is triggered each time you push changes to your GitHub repository. You can access the complete application code on GitHub.
If you want to go more in-depth with Fauna and Flask, check out this great example shop Fauna has created: fauna-labs/fauna-shopapp-flask. It was the inspiration for this tutorial! Also, check out Fauna's documentation for more information on how to use Fauna's ABAC system.
If you would like to read more Koyeb tutorials, checkout out our tutorials collection. Have an idea for a tutorial you'd like us to cover? Let us know by joining the conversation over on the Koyeb community platform!

