Scale-to-Zero: Wake VMs in 200ms with Light Sleep, eBPF, and Snapshots
At Koyeb, we run a serverless platform for deploying production-grade applications on high-performance infrastructure—GPUs, CPUs, and accelerators. You push code or containers; we handle everything from build to global deployment, running workloads in secure, lightweight virtual machines on bare-metal servers around the world.
Last week, we announced a major milestone in the ongoing journey of optimizing efficiency and cold starts: Light Sleep, which reduces cold starts to around 200ms for CPU workloads.
To get there, during the last months, we had to rethink how we deploy apps, rewire how the network stack behaves when nothing is running, add snapshotting, lean heavily on some eBPF tricks, and work around a bunch of uncommon issues along the way. (Spoiler: networking is hell.)
In this post, we’ll walk through our journey to bring 200ms cold starts on Koyeb — from the exact problems we hit, to why eBPF became our secret weapon, and how we got Scale-to-Zero working with near-zero cold starts.
What we started with (and why it wasn’t enough)
If you’ve followed us for a while, you probably know we used to rely on Firecracker: a lightweight virtual Machine Monitor (VMM) created by AWS that runs on top of the Linux kernel. It blends the security of traditional VMs with the speed and efficiency of containers. Firecracker is an excellent fit for multi-tenant environments because it's small, fast, and safe. But Firecracker comes with a few limitations, specifically around PCI passthrough and GPU virtualization, which prevented Firecracker from working with GPU Instances. At Koyeb, we provide a unified, hardware-agnostic experience to deploy across CPUs, GPUs, and accelerators.
To keep our infrastructure consistent and flexible, we needed a virtualization layer that works across all workloads. That's why we moved away from Firecracker in favor of Cloud Hypervisor.
Cloud Hypervisor is a modern VMM with broader hardware support and a more modern codebase. But as is usually the case, solving one set of problems introduced another.
A more flexible setup with Kata Containers
One of the key lessons we learned from migrating to Cloud Hypervisor was that we needed a more flexible setup. Today we’re using Cloud Hypervisor — tomorrow, it might be something else.
To support that flexibility, we introduced Kata Containers into our stack. Kata gives us an abstraction layer over the VMM, allowing us to easily swap between different backends like Firecracker, Cloud Hypervisor, or even QEMU in the future.
Kata acts as the glue between containers and VMs by providing a container runtime we interface with via containerd, plugged into Nomad. With this setup, Nomad can launch tasks and use Kata to spin up Cloud Hypervisor VMs, treating them just like regular containers.
Here’s a great illustration of how Kata Containers stitch together the container world and the VM world:
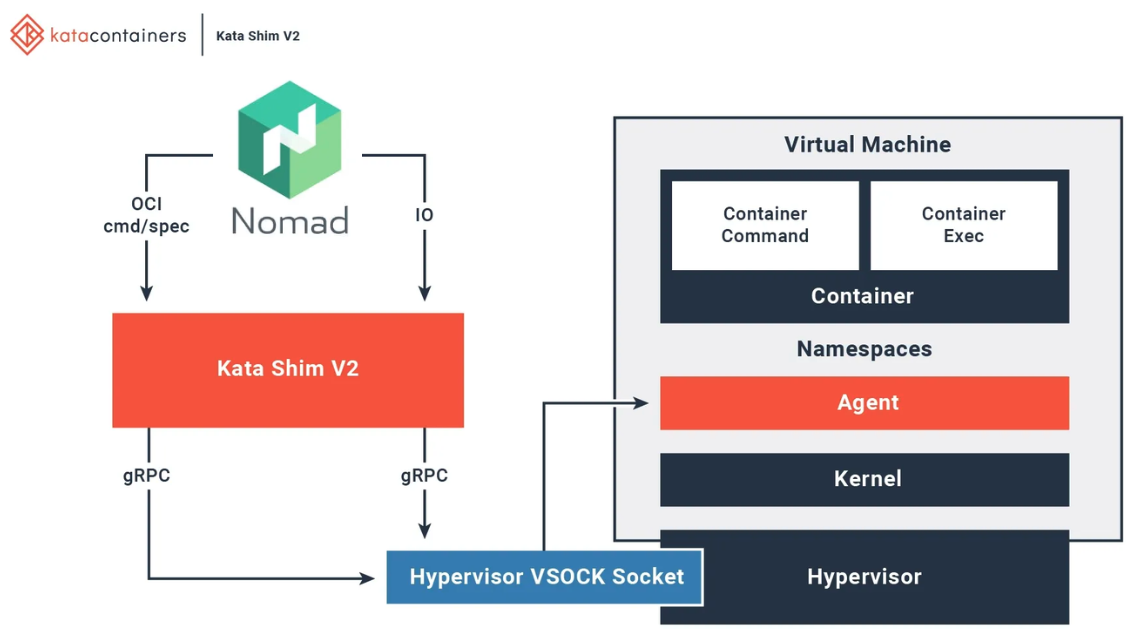
The Kata shim is the core of what makes this solution work.
Kata’s shim (containerd-shim-kata-v2) plugs directly into containerd, acting like a bridge between the container world and the VM world, which makes VMs look and behave like regular OCI containers.
Naturally, the shim became the perfect place to wire in our snapshotting logic. We added support for two new endpoints:
pause_with_snapshot: pauses the VM and writes a snapshot to diskresume_from_snapshot: resumes the VM from a snapshot
And since Cloud Hypervisor has built-in snapshot support, we naturally assumed that implementing snapshots for Koyeb Instances would be easy.

Problem #1 - virtio-fs: Great until it's not
With our previous configuration, were using virtio-fs - a shared filesystem that lets VMs access directories on the host. It made a lot of things simpler, as there was no need to mess with block devices or set up complex mounts.
But it turned out virtio-fs breaks snapshot restore in Cloud Hypervisor. Specifically, the virtio-fs device couldn’t be reattached after resuming from snapshot due to this bug.
After multiple attempts to work around the issue, we needed to invest time on other features, so we make the hard call to drop virtio-fs for now. Thankfully, we managed to keep all the features we needed without it.
Problem #2 - Restoring the network was supposed to be easy
The Cloud Hypervisor docs made it sound simple:
Just pass the net device file descriptors when calling the
restoreendpoint and everything will work.
Spoiler: it didn’t.
After digging into how snapshotting was implemented, we realized Cloud Hypervisor relies on SCM_RIGHTS - a mechanism to pass file descriptors between processes over Unix sockets.
For the network to work inside the VM after a restore, we need to give the VM a list of network file descriptors residing on the host. The catch is that Cloud Hypervisor’s restore HTTP API does not allow you to restore with file descriptors. You have to first restore using the HTTP API and then send a control message Cloud Hypervisor’s control socket to pass the network sockets.
So we opted to dive into Kata internals and wire up the inter-process communication (IPC) ourselves to get networking back after calling restore. We patched the Kata Containers restore endpoint to run a subprocess ch-remote restore which restores the VM. The subprocess ch-remote gets the network file descriptors using linux’s ExtraFiles.
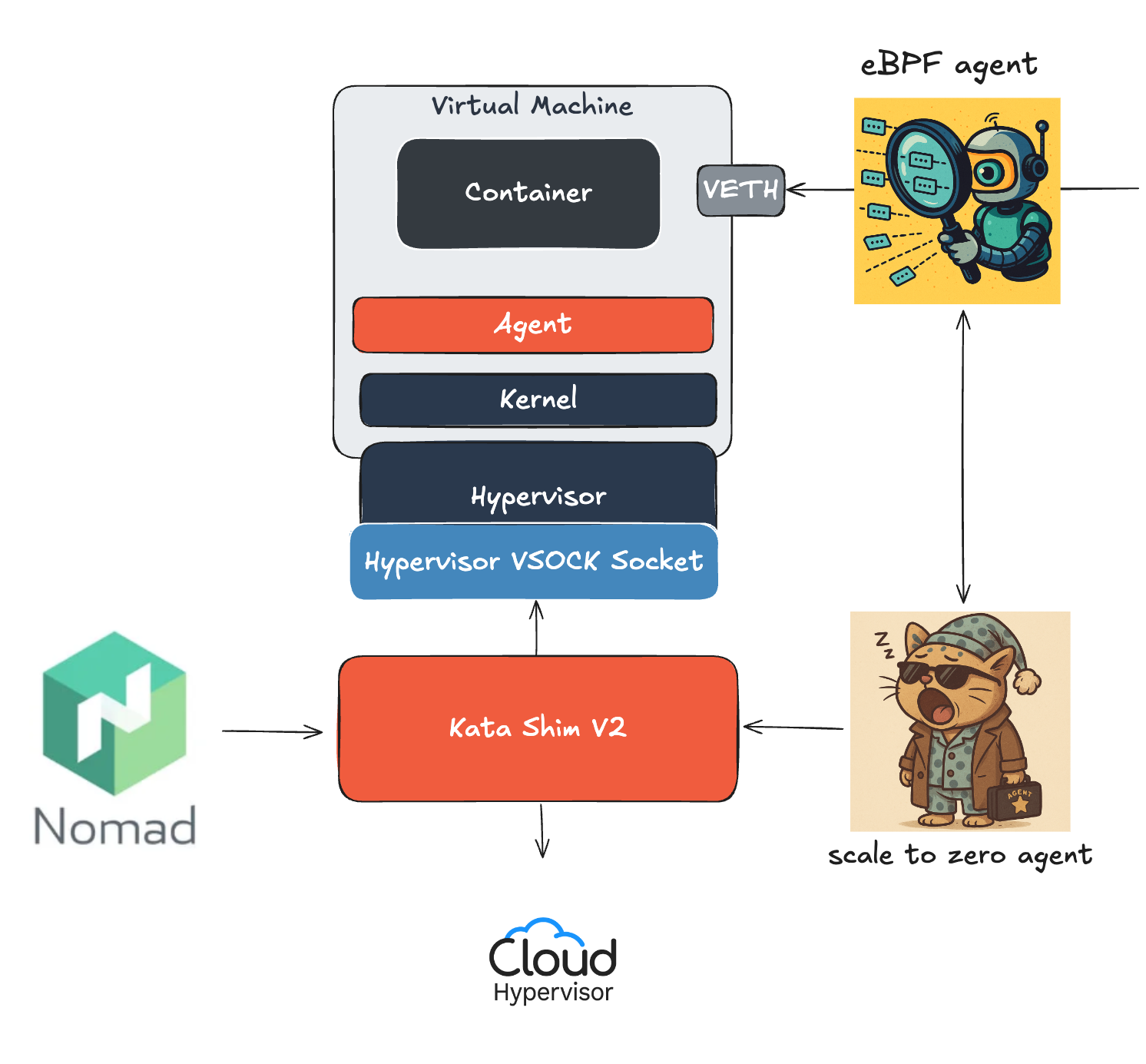
Waking sleeping services with eBPF (and a bit of pain)
With snapshotting mechanisms in place, we had the ability to pause and resume VMs on demand using our two new endpoints, pause_with_snapshot and `resume_with_snapshot.
We now needed to add the next layer to decide when and how to pause and resume workloads, especially without breaking health checks, traffic, or orchestration.
Scaling to zero sounds simple in theory. In practice, here’s what we actually had to handle:
- Detect when an Instance has been idle for too long
- Make sure health checks don’t count as real traffic
- Find a safe place to run the "pause" logic
- Prevent Nomad from marking the allocation as "unhealthy" while it’s sleeping
- Wake the Instance up instantly on real traffic
Each of these turned out to be a minefield. Here’s how we solved them.
Kernel-level idle detection with eBPF
To detect whether an Instance is truly idle, we inject an eBPF program into every node. This program watches for inbound packets and increments counters for a given instance. eBPF allows sandboxed programs to run within the operating system, which means that application developers can run eBPF programs to add additional capabilities to the operating system at runtime.
Alongside the eBPF program, we run a lightweight daemon — scaletozero-agent — that monitors those counters. If no new packets show up for a set period, it initiates the sleep process.
No polling. No heuristics. Just fast, kernel-level idle detection.
Health checks can’t keep a service awake forever
To determine the health of an app, we run periodic health checks via Consul. The problem with this method is that those checks generate real traffic. If we treated them like any other request, our services would never qualify as idle and thus never sleep.
So we taught the kernel to ignore them.
We use the sk_buff.mark field — a kernel-level metadata flag on packets - to tag health check traffic. We do this using a simple iptables rule that marks packets from Consul using one of the bits.
Our eBPF program inspects each packet, and if the mark is set, it skips counting it. This way, health checks keep flowing, but they no longer keep services awake.
Putting apps to sleep: from detection to action
Once we could detect real inactivity using eBPF, the next challenge was determining what component actually initiates going to sleep.
For this task, we used our to scaletozero-agent, our lightweight daemon running on each node. It continuously monitors the packet counters updated by our eBPF program. When no real traffic is observed for a configurable period, the agent initiates the sleep sequence.
It does this by calling the local containerd API to invoke pause_with_snapshot which:
- Saves the full VM state to disk
- Updates the shared eBPF map to mark the service as sleeping
This gave us a clean, deterministic way to pause apps automatically without interfering with orchestration or networking.
Sleeping containers fail health checks…and everything breaks
When a container is paused, no process is running, so it can’t respond to health checks.
We use Nomad to orchestrate workloads across our infrastructure, and it expects tasks to respond to periodic health checks.
When they don’t, Nomad assumes the allocation is unhealthy and tries to restart it, which completely defeats the purpose of putting apps to sleep.
To work around this behavior, we intercept health check traffic at the eBPF level.
If the service is asleep, we proxy the check to a dummy HTTP server (running locally as part of scaletozero-agent) that always returns 200 OK.
This way, we're able to avoid Nomad from marking the allocation as unhealthy and rescheduling it.
Waking up instantly on real traffic without breaking clients
Now we need to detect incoming traffic and wake the Service up — fast.
Our eBPF program tracks each Instance’s status (Sleeping or Running) using a shared map updated by scaletozero-agent.
When it sees real traffic headed for a sleeping Service, it signals the agent.
The agent runs resume_from_snapshot, updates the status, and brings the Service back online.
It looks simple, but there’s a twist:
The first packet hits a dead end because the Instance is still in the process of waking up. But TCP — being the persistent little protocol it is — retries. And by the time the next attempt lands, the service is live.
We don’t pause the request or fake a delay, we just let the network stack do the heavy lifting.
What’s next: bringing snapshotting to GPU-based Services
Building real Scale-to-Zero wasn’t just about snapshotting VMs or wiring up eBPF; it was about rethinking how every part of the stack behaved when nothing is supposed to be running.
Achieving ~200ms boot times wasn’t simple. From VM snapshotting to kernel-level networking quirks to keeping Nomad happy, we had to rework major parts of the system.
With snapshotting and eBPF, Scale-to-Zero is now live in public preview on Koyeb, delivering near-instant wakeups and eliminating wasted compute when apps are idle, all without breaking the developer experience.
Next up is extending snapshotting to GPU-based Services, which introduces a whole new layer of complexity, especially around preserving VRAM, which is something not all hardware supports yet.
We’re making steady progress, but there’s still more to figure out.
Try it today and watch your apps scale to zero, save compute, and wake instantly, without anyone noticing.