Best LLM Inference Engines and Servers to Deploy LLMs in Production
AI applications that produce human-like text, such as chatbots, virtual assistants, language translation, text generation, and more, are built on top of Large Language Models (LLMs).
If you are deploying LLMs in production-grade applications, you might have faced some of the performance challenges with running these models. You might have also considered optimizing your deployment with an LLM inference engine or server.
Today, we are going to explore the best LLM inference engines and servers available to deploy and serve LLMs in production. We'll take a look at vLLM, TensorRT-LLM, Triton Inference Server, RayLLM with RayServe, and HuggingFace Text Generation Inference.
Important metrics for LLM serving
- Throughput: The number of requests from end users processed per second. Also measurable by the number of tokens generated by the model you are using in your application.
- Latency: The time taken to process a request from the time it is received to the time the response is sent. TTFT (Time to First Token) is a key metric for measuring the latency of LLMs.
The hard truth about serving LLMs in production is that latency can be long and throughput can be sub-optimal.
All GPUs have a limited amount of memory, and memory is needed for model parameters, results stored in KV cache, and entire batch computations. Without optimizing any of these components, they all compete for precious memory space.
And in worst-case scenarios, they create out-of-memory errors, which crash the server and degrade your application's performance.
LLM inference engines and servers are designed to optimize the memory usage and performance of LLMs in production. They help you achieve high throughput and low latency, ensuring your LLMs can handle a large number of requests and deliver responses quickly.
Knowing which one you should use depends on your specific use case, the size of your model, the number of requests you need to handle, and the latency requirements of your application.
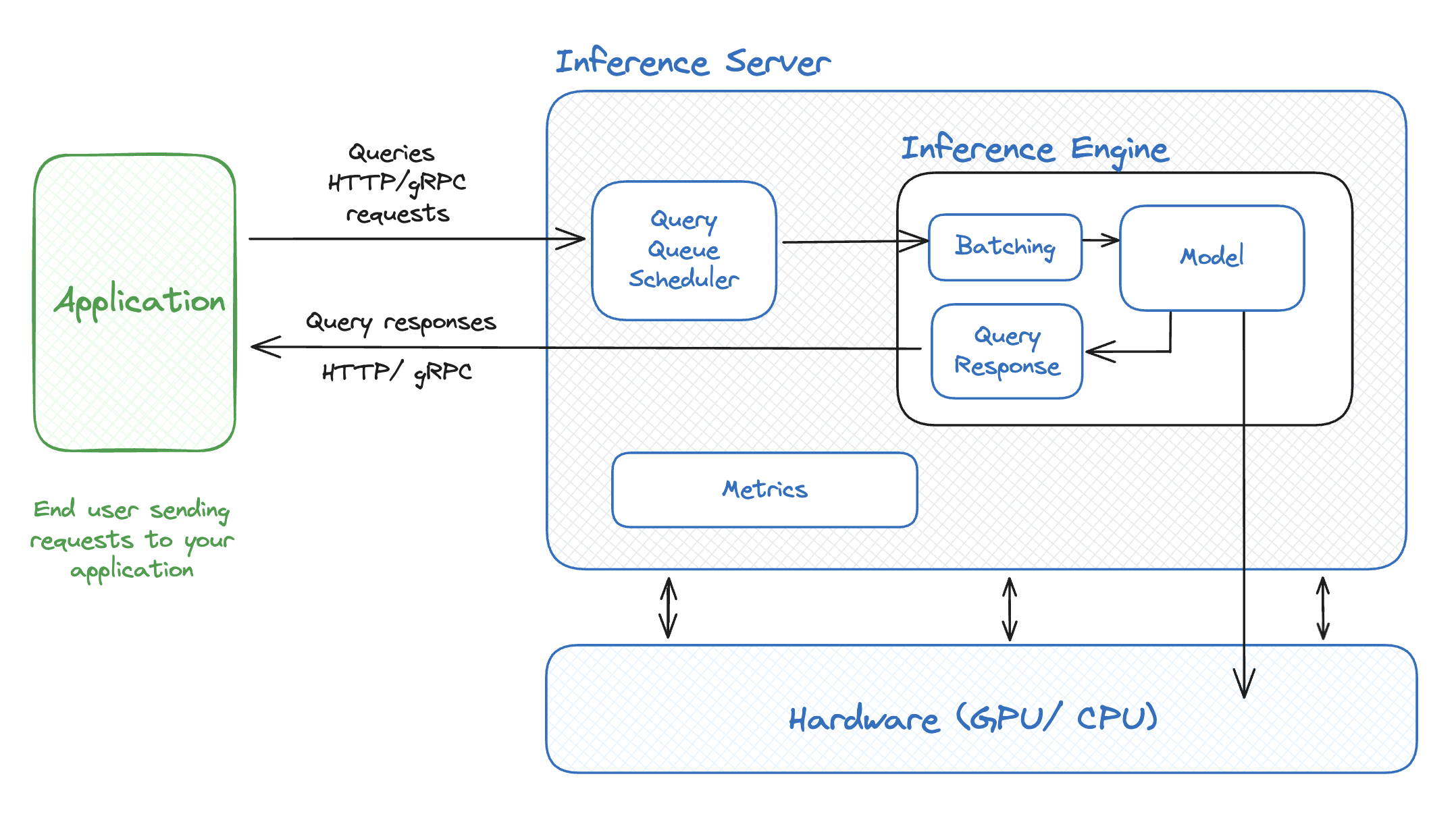
What is the difference between inference engines and inference servers?
The most important thing to remember about what distinguishes inference engines and servers:
- Inference Engines run the models and are responsible for everything needed for the generation process
- Inference Servers handle the incoming and outgoing HTTP and gRPC requests from end users for your application, collect metrics to measure your LLM's deployment performance, and more.
Here is a simplified overview of their architecture and how they work together with your application:
Best LLM Inference Engines
1. vLLM
Last year, researchers from UC Berkeley released vLLM, an open-source inference engine that speeds up LLM inference and serving in production. vLLM leverages PagedAttention, an attention algorithm introduced by the research team based on virtual memory and paging in operating systems.
Applying this PagedAttention when serving LLMs greatly improves the LLM's throughput. When vLLM was released, benchmarks showed how it provided 24x higher throughput compared to HuggingFace Transformers and 3.5x higher throughput than HuggingFace Text Generation Inference.
How is it faster?
- The performance improvements are due to the attention algorithm, PagedAttention, which borrows from the classic solution of virtual memory and paging in operating systems.
- Efficient KV cache
- Continuous batching
- Quantization
- Optimized CUDA kernels
Helpful resources
- GitHub repository: https://github.com/vllm-project/vllm
- Documentation: https://docs.vllm.ai/en/latest/index.html
2. TensorRT-LLM
Created by NVIDIA, TensorRT-LLM is an open source inference engine that optimizes the performance of production LLMs. It is an easy-to-use Python API that looks similar to the PyTorch API.
Several models are supported out of the box, including Falcon, Gemma, GPT, Llama, and more.
An important limitation of TensorRT LLM is that it was built for Nvidia hardware. Also, whichever GPU you use to compile the model, you must use the same for inference.
How is it faster?
- Leverages PagedAttention, which frees up memory allocation more dynamically than traditional attention approaches.
- In-flight batching
- Paged Attention
Helpful resources
- GitHub repository: https://github.com/NVIDIA/TensorRT-LLM
- Documentation: https://nvidia.github.io/TensorRT-LLM/
Deploy AI inference workloads backed by high-end serverless GPUs in minutes.
Best Inference Engine and Server
1. Hugging Face Text Generation Inference
A solution for deploying and serving from HuggingFace. TGI (Text Generation Inference) uses Tensor Parallelism and dynamic batching to improve performance. Models optimized for TGI include: Llama, Falcon, StarCoder, BLOOM, and more.
How is it faster?
- Tensor parallelism when running on multiple GPUs
- Token streaming using SSE
- Continuous and dynamic batching
- Flashed and Paged attention
Helpful resources
- GitHub repository: https://github.com/huggingface/text-generation-inference
- Documentation: https://huggingface.co/docs/text-generation-inference/en/index
2. RayLLM with RayServe
RayLLM is an LLM serving solution for deploying AI workloads and open source LLMs with native support for continuous batching, quantization, and streaming. It provides a REST API similar to the one from OpenAI, making it easy to cross test.
RayServe is a scalable model for building online inference APIs. Ray Serve is built on top of Ray, allowing it to easily scale to many machines. Ray Serve has native support for autoscaling, multi-node deployments, and scale to zero in response to demand for your application.
Supports multiple LLM backends out of the box, such as vLLM and TensorRT-LLM.
How is it faster?
- Continuous batching, quantization, and streaming with vLLM
- Out-of-the-box support for vLLM and Tensor-RTLLM
Helpful resources
- GitHub repository: https://github.com/ray-project/ray-llm
- Documentation: https://docs.ray.io/en/latest/serve/index.html
3. Triton Inference Server with TensorRT-LLM
Created by NVIDIA, Triton Inference Server is an enterprise offering that accelerates the development and deployment of LLMs in production.
TensorRT LLM is an open source framework created by Nvidia to optimize LLMs performance in production. TensorRT-LLM does not serve the model using raw weights. Instead, it compiles the model and optimizes the kernels to efficiently serve.
An important caveat about this solution is that it built for Nvidia GPU only. Plus, whichever GPU hardware you use to complie the model, you must use the same for inference. Lastly, TensorRT LLM does not support all LLMs out of the box. Mistral and Llama are supported.
How is it faster?
- Paged attention
- Efficient KV caching
- Dynamic batching
- Concurrent model execution
- Out-of-the-box support for multiple deep learning and machine learning frameworks
- Metrics for GPU utilization, server throughput, server latency, and more
Helpful resources
- GitHub repository: https://github.com/triton-inference-server/server
- Documentation: https://docs.nvidia.com/deeplearning/triton-inference-server/user-guide/docs/index.html
Enjoy automatic continuous deployment, global load balancing, real-time metrics and monitoring, autoscaling, and more.
Deploy on high-performance AI infrastructure
Run LLMs, computer vision, and AI inference on high-end GPUs and accelerators in seconds. Our platform is bringing the best AI infrastructure technologies to you.
Go from training to global inference in seconds. Enjoy the same serverless experience you know and love: global deployments, automatically scale to millions of requests, build with your team, leverage native advanced networking primitives, zero infrastructure management, and pay only for the resources you use.
Ready to deploy your AI workloads on the best AI hardware from NVIDIA, AMD, Intel, and more? Join our Serverless GPU private preview to get access today.